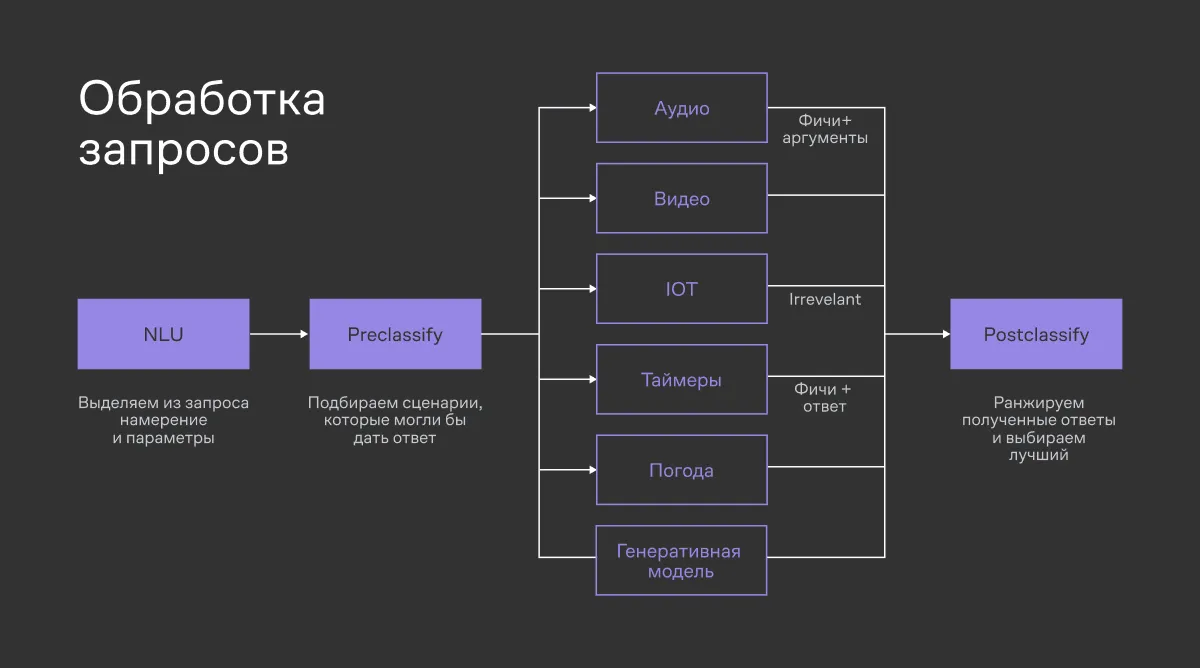
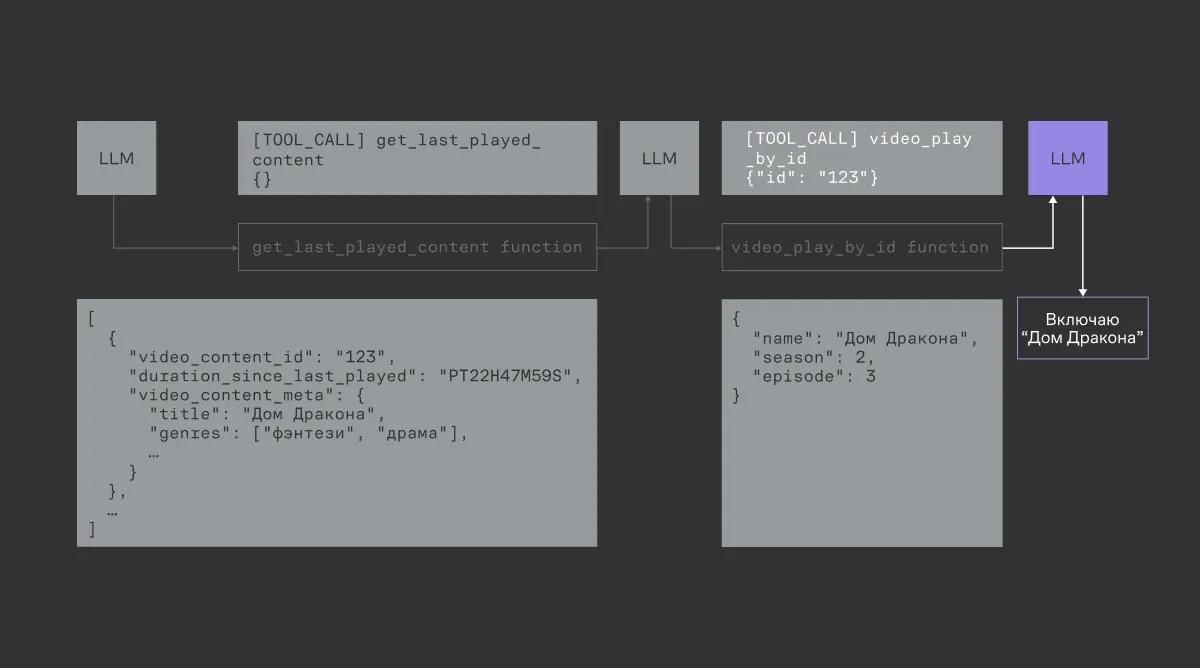
Новая технология позволила команде запустить полноценное голосовое управление графическим интерфейсом на ТВ-станции. Модели дали доступ к контексту всего экрана и способность «нажимать» на любые элементы. Это первый шаг к бесшовному взаимодействию, при котором наличие пульта становится опциональным.
Блиц для Паши!
А ещё мы задали Паше пару вопросов — просто не могли удержаться!
Ты работаешь в Яндексе с 2018 года. Расскажи, на какую работу приходил изначально и чем занимаешься сейчас?
Я пришёл на позицию Java-разработчика и занимался сервисом, отвечал за продажу и покупку фильмов и подписки в Алисе, а также выдачу промокодов новым владельцам устройств. Сейчас я возглавляю всю продуктовую разработку Алисы, строю и превращаю технологии в продукты, с которыми взаимодействуют все пользователи.
Сколько лет занял переход Алисы с одной архитектуры на другую? Насколько большая команда работала над проектом?
Первый концепт появился летом 2023, в проекте участвовало несколько десятков разработчиков, ML-инженеров, аналитиков, менеджеров и QA.
Какие у вас планы на ближайшее время? На чём планируете сосредоточиться в 2026 году?
Недавно мы запустили новое семейство моделей Alice AI и анонсировали агентов на основе этих моделей, которые скоро появятся у наших пользователей. Кстати, проект с реализацией и внедрением Function calling стал базовым кирпичиком, из которого они выросли.
Что посоветуешь тем, кто только начинает свой путь в IT?
Найти себе проект, от которого будешь кайфовать, чувствовать отдачу и гордиться. А потом не побояться на него податься и сделать всё, чтобы заниматься именно им.