Привет, Homo Computius!
Мы люди, живущие в сети. А большинство вещей, которые мы видим вокруг себя, созданы с помощью компьютеров (включая этот текст). Спорим, вы сейчас читаете его на мониторе, экране ноутбука или смартфона! Или планшета. Но если вы сперва распечатали его, а после пошли читать — наше увожение.
Компьютеры уже давно стали водой и воздухом современного мира. Мы тут листали недавно журналы 40-летней давности и нашли там фразу «Компьютерные технологии уже прочно вошли в нашу жизнь». И без них никуда — даже не очень-то понимая, как они на самом деле устроены. А мы вам сейчас расскажем! Подготовили подробное руководство по тому, как там всё внутри работает:
- Начнём с небольшого исторического экскурса — про то, как люди перемножали числа 100 и даже 200 лет назад и грезили о роботах ещё до изобретения электричества.
- После покажем, как от вычислительных задач компьютеры прыгнули к творческим: как они понимают музыку или изображения — и создают собственные.
- Бонус-трек — гайд по операционным системам и языкам программирования.
Вот такой вот букет статей от 8БИТ — в нашем стиле. И с иллюстрациями, которые для нас создал художник-человек. Поехали!
Если после этого захочется копнуть глубже, откройте хендбук «Введение в компьютерные науки» от Яндекс Музея. Всё подано просто и интерактивно: листаешь, читаешь, пробуешь и закрепляешь знания на практике.

Архитектура компьютеров: чем современные компьютеры похожи на совсем древние
Говорим «архитектура» — подразумеваем здания. Но в компьютерных делах архитектура тоже бывает — правда, внутренняя: это компоненты, из которых состоит компьютер, и их взаимодействие друг с другом.
Всё это не зря называют архитектурой. Когда-то сами компьютеры были размером с дом!
Пожалуй, с этого и начнём.
Первые компьютеры — и их первые проблемы
Первой универсальной ЭВМ был ENIAC (Electronic Numerical Integrator and Computer, «электронный цифровой интегратор и вычислитель»), который закончили к 1945 году.
Он весил почти 30 тонн и содержал около 18 тысяч электронных ламп. Ни клавиатуры, ни монитора не было, компьютером управляли с помощью тумблеров на огромных коммуникационных панелях. На подготовку расчёта, который мог занять у ЭВМ всего несколько минут, уходили часы, а порой и дни.
Главные разработчики ENIAC, Джон Мокли и Джон Преспер Эккерт из Пенсильванского университета, понимали недостатки своего детища ещё в 1943 году.
 Счастливые Джон Мокли и Джон Преспер Эккерт держат в руках блок от ENIAC, отвечающий за работу с одним десятичным разрядом
Счастливые Джон Мокли и Джон Преспер Эккерт держат в руках блок от ENIAC, отвечающий за работу с одним десятичным разрядом
Мокли и Эккерт начали думать над будущими компьютерами ещё до запуска «Эниака». Чтобы побороть один из главных недостатков — длительный и неудобный процесс перепрограммирования — Эккерт предложил хранить саму программу вычислений в той же памяти, что и данные, необходимые для расчёта. Назвать более совершенную машину предполагалось EDVAC (Electronic Discrete Variable Automatic Computer, «электронный дискретный настраиваемый автоматический вычислитель»). Она, конечно, тоже была размером с дом: лампы требуют много места.
Архитектура фон Неймана
В сентябре 1944 года к разработчикам ENIAC присоединился Джон фон Нейман — выдающийся американский математик и участник Манхэттенского проекта.
Фон Нейман был единственным участником проекта, который не появился в фильме «Оппенгеймер» Нолана. Потому что он был бы довольно скучным персонажем: математика интересовали не интриги, а формулы.
 Джон фон Нейман в 1952 году на фоне компьютера IAS machine
Джон фон Нейман в 1952 году на фоне компьютера IAS machine
Он довольно быстро вник в суть и также стал приверженцем идеи хранимой в памяти программы. Чтобы добиться финансирования перспективной разработки, нужно было заручиться поддержкой военных.
Фон Нейман составил «Черновик доклада об EDVAC» (First Draft of a Report on the EDVAC), в котором описал основные архитектурные принципы:
- В состав компьютера входит устройство для выполнения арифметических операций, устройство управления, память, устройства ввода и устройства вывода.
- Программы состоят из команд, каждая из которых требует от компьютера выполнить одну из доступных ему операций.
- По умолчанию команды выполняются последовательно, но этот порядок можно изменить за счёт выполнения специальных команд.
- И данные, и команды хранятся в памяти. Над командами можно выполнять те же действия, что и над данными.
- Память состоит из пронумерованных ячеек, к каждой из которых можно обратиться по её адресу.
- Данные и команды представлены в двоичной системе счисления.
В общем, фон Нейман описал принципы, по которым работают сегодня все вычислительные устройства: от стиральных машин до суперкомпьютеров. Голова!
Отчёт поступил математику Герману Голдстайну, курировавшему проект со стороны военных. Тот был настолько впечатлён перспективностью изложенных идей, что в июне 1945 года решил разослать копии отчёта разным учёным, не спрашивая разрешения разработчиков и не вникая в тонкости авторства. В итоге на титульном листе отчёта осталась лишь фамилия составителя — Джона фон Неймана. С лёгкой руки Голдстайна изложенный в документе подход к конструированию компьютеров стал известен как «архитектура фон Неймана».
В СССР независимо от Джона фон Неймана к тем же выводам касательно оптимального устройства ЭВМ в конце 1940-х годов пришёл Сергей Лебедев. В Германии схожие принципы сформулировал Конрад Цузе, хотя от идеи совместно хранить программы и данные в памяти он всё же отказался.
Из-за ухудшения отношений между фон Нейманом, Эккертом и Мокли работа над постройкой EDVAC сильно затормозилась. В итоге первый компьютер с фоннеймановской архитектурой был создан не в США, а в Великобритании. Он получил название EDSAC (Electronic Delay Storage Automatic Calculator, «электронный автоматический вычислитель с памятью на линиях задержки»).
 EDSAC, 1949 год. Компьютер всё ещё похож на шкафы с коллекцией ламп и проводочков
EDSAC, 1949 год. Компьютер всё ещё похож на шкафы с коллекцией ламп и проводочков
EDSAC навсегда останется в истории вычислительной техники не только как одна из первых ЭВМ современного типа, но и как первый компьютер, для которого была написана компьютерная игра. Сегодня мы знаем её как OXO либо Noughts and Crosses — это был вариант хорошо всем известных крестиков-ноликов.
 Noughts and Crosses на экране электронно-лучевой трубки компьютера EDSAC
Noughts and Crosses на экране электронно-лучевой трубки компьютера EDSAC
Устройство компьютера
Хотя Джон фон Нейман в своём отчёте выделял пять основных частей компьютера, в современной информатике их обычно упрощают до трёх. Арифметическое устройство и устройство управления вместе принято называть процессором.
Процессор — основное устройство компьютера, выполняющее заданные программой арифметические и логические операции и управляющее периферийными устройствами.
Устройства ввода и устройства вывода тоже можно объединить в одну группу. Таким образом, обязательные части любого компьютера — это:
- Процессор.
- Память.
- Устройства ввода-вывода.
В общем, всё как сегодня. Правда, сейчас всю логику ЭВМ первого поколения, таких как ENIAC и EDVAC, можно «зашить» в крошечную микросхему, которую получится увидеть только в микроскоп.
 Миниатюризация базовых элементов электроники на картинке из рекламной брошюры IBM
Миниатюризация базовых элементов электроники на картинке из рекламной брошюры IBM
Процессор современного компьютера — это одна микросхема размером с почтовую марку. Если, конечно, вы ещё помните, что это такое.

Функции памяти выполняют несколько разных устройств: модули оперативной памяти и накопители. Обо всём этом мы обязательно скоро расскажем!
P.S. Спасибо, мистер фон Нейман!
Как считали древние люди
Где математика, там жизнь (и наоборот). Но как быть, если у тебя под рукой нет калькулятора, потому что его ещё не изобрели? А мы сейчас расскажем! Но сперва договоримся об определениях
Где начинается компьютерная эра
Компьютерную эру в истории человечества отсчитывают с середины 1940-х годов.
Историки спорят о том, что считать первым компьютером: в числе кандидатов называют не только американский ENIAC (1945), но и немецкий Z3 Конрада Цузе (1941) и некоторые другие разработки.
Так или иначе, всё это автоматические цифровые вычислительные машины, способные выполнять любые корректные программы. Все слова в предыдущем предложении важны: если убрать любое из них, мы получим описание устройства, которое компьютером может уже и не быть.
Если исключить исполнение произвольных программ, под такое описание подойдут специализированные вычислители, пригодные для решения только одного класса задач. Например, британские машины Bombe (1940) и Colossus (1943), которые служили для дешифрования немецких криптограмм. Справедливости ради стоит отметить, что ограниченные возможности программирования у «Колосса» всё же были.
Если убрать слово «цифровые», перед нами откроется семейство аналоговых вычислительных машин, которые появились задолго до компьютеров и какое-то время развивались с ними параллельно. Самый древний известный нам пример такого устройства — антикитерский механизм (II в. до н. э.). Это был сложный астрономический календарь, моделирующий движение небесных тел и позволяющий вычислять даты разных астрономических событий и важнейших праздников.
Куда более известны другие аналоговые приспособления — логарифмические линейки. С помощью таких линеек можно получать только приблизительные результаты (обычно 3–4 значащие цифры), но для множества практических задач большего и не требовалось. Поэтому вплоть до второй половины XX века логарифмические линейки были неизменным атрибутом инженеров, конструкторов и навигаторов.
Рассказывали о логарифмической линейке в специальной статье 8БИТ, инджой!
 Логарифмическая линейка
Логарифмическая линейка
В основе работы таких линеек — возможность заменить умножение и деление чисел сложением и вычитанием их логарифмов. Для этого нужно перемещать движок и бегунок (визир) линейки, подводя их к нужным рискам на её шкалах.
Точность вычислений на логарифмической линейке определяется только её размером и качеством изготовления. В этом основное отличие аналоговой техники от дискретной, в которой вычисление всегда можно произвести с точностью до нужного количества значащих цифр.
Пятиминутка определений. Дискретный — прерывистый, работающий с отдельными значениями/состояниями. Антоним слова «аналоговый». Все современные цифровые устройства также корректно называть дискретными.
В конце XIX века появились аналоговые машины для предсказания приливов, которые при помощи колёс разного диаметра и системы тросов учитывали влияние десятка факторов (самые важные — гравитация Луны и Солнца).
В 1930-х появились дифференциальные анализаторы — механические аналоговые устройства, позволяющие решать дифференциальные уравнения.
 Внешне такая машина напоминала гигантский настольный футбол. Программист выигрывает в нём не всегда
Внешне такая машина напоминала гигантский настольный футбол. Программист выигрывает в нём не всегда
Больше всего созданием подобных вычислителей прославился американский инженер Вэнивар Буш (он, кстати, также считается изобретателем гипертекста), но вообще их разрабатывали во многих промышленно развитых странах. Например, в СССР инженер-электротехник Исаак Брук в 1939 году построил машину для решения систем дифференциальных уравнений до шестого порядка включительно.
Наконец, если убрать из определения слово «автоматические», мы получим огромное многообразие дискретных вычислительных устройств докомпьютерной эпохи, которые не умели работать по программе — только выполнять отдельные действия. В их числе «считающие часы» Вильгельма Шиккарда, «паскалина», «машины Тома», «самосчёты» Виктора Буняковского, «математическая граната» и прочие арифмометры всех видов, форм и расцветок.
 Арифмометр Шарля Тома де Кольмара — первый коммерчески успешный (1840‑е). Каков дизайн, а!
Арифмометр Шарля Тома де Кольмара — первый коммерчески успешный (1840‑е). Каков дизайн, а!
Одну из самых практичных и распространённых конструкций арифмометра предложил шведско-российский изобретатель Вильгодт Теофил Однер. Многим известен советский вариант арифмометра Однера — «Феликс». Эти машины позволяли выполнять четыре основные арифметические операции — сложение, вычитание, умножение и деление, а при определённой сноровке — и извлекать квадратный корень, но самим ходом вычисления всегда управлял человек.
Инструкция к арифмометру «Феликс» рекомендовала использовать его только для умножения и деления, так как более простые операции можно было выполнить и на счётах.
Типичный «вычислительный центр» 1940-х годов представлял собой помещение со множеством небольших столиков, на которых люди-расчётчики (как правило, женщины) с утра до вечера выполняли однотипные операции, нажимая на кнопки и вращая ручки механических счётных машинок.
 Иронично, что в англоговорящих странах сотрудников таких учреждений называли словом computer («вычислитель»)
Иронично, что в англоговорящих странах сотрудников таких учреждений называли словом computer («вычислитель»)
В послевоенные годы в СССР попало множество трофейных немецких арифмометров с электрическим приводом. Это даже нашло отражение в культуре. Например, у братьев Стругацких:
В Управлении пьют кефир, считают на сломанных «Мерседесах», издают странные распоряжения... («Улитка на склоне»)
...слышно было, как пишущие машинки вяло и неубедительно отвечают на энергичные напористые очереди бухгалтерских «Рейнметаллов». («Сказка о Тройке»)
Речь, конечно, не об автомобилях и не о пулемётах, а о вычислительных машинах производства соответствующих фирм.
Не только арифметика
А как же перфокарты? Так вот же они.
Перфокарта — небольшая карточка из плотного картона, предназначенная для хранения данных в виде комбинации отверстий.
Хотя эти носители цифровой информации прочно ассоциируются со старыми ЭВМ, сами по себе перфокарты намного старше компьютерной техники. И речь не о тех перфокартах, что использовались в ткацких станках Вокансона и Жаккара для кодирования узоров.
 Ткацкий станок Жаккара, управляемый перфокартами, начало 1800-х. Дизайн Дизайныч!
Ткацкий станок Жаккара, управляемый перфокартами, начало 1800-х. Дизайн Дизайныч!
Ещё с конца XIX века перфокарты стали применять для обработки, как сказали бы сегодня, больших данных. Специальные машины — табуляторы и сортировщики — позволяли автоматически подсчитывать количество перфокарт с определёнными признаками, суммировать нанесённые на них значения и упорядочивать карты по тем или иным параметрам. На одной карточке могла храниться информация об одном человеке, товаре или банковской операции.
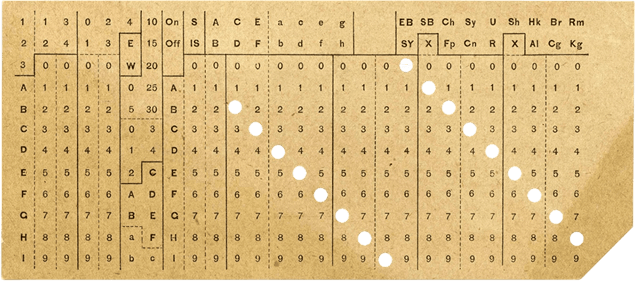 Перфокарта Холлерита
Перфокарта Холлерита
Первопроходцем здесь был Герман Холлерит, а основанная им компания после ряда слияний и переименований стала известна как IBM. Вообще же первым использовать перфокарты для анализа и поиска информации ещё в 1832 году предложил российский чиновник Семён Корсаков. К сожалению, тогда его идеи не встретили поддержки.
Один из самых старых сохранившихся табуляторов оригинальной конструкции Холлерита хранится в Политехническом музее в Москве. Он использовался для проведения первой всеобщей переписи населения Российской империи в 1897 году.
 Иллюстрация из журнала Scientific American: радостная операторка табулятора Холлерита считает население. Справа в коробках не пиццы, а листы переписи
Иллюстрация из журнала Scientific American: радостная операторка табулятора Холлерита считает население. Справа в коробках не пиццы, а листы переписи
Табуляторы IBM также упоминаются в литературе. Например, в романе «Уловка-22» Джозефа Хеллера из-за ошибки машины рядовой с экзотическим именем Майор Майор автоматически получил звание майора.
А вот основным инструментом торговли до массового распространения микрокалькуляторов были обычные счёты (а также их национальные разновидности — суаньпань, соробан и другие). Куда реже применялись аддиаторы («счислители Куммера»). При отсутствии же любых приспособлений пользовались традиционным школьным умножением и делением в столбик либо просто считали в уме.
Немного стимпанка
Возможно, вы обратили внимание, что в наше определение компьютера не вошло слово «электронная». Хотя все окружающие нас сегодня компьютеры — электронные, строго говоря, это не обязательное условие.
Самые ранние компьютеры вроде Z3 и Harvard Mark I были ещё не электронными, а электромеханическими. Более того, «Аналитическая машина», которую в XIX веке спроектировал британец Чарльз Бэббидж, и вовсе должна была быть чисто механической и приводиться в действие паровым двигателем. При этом, будь она построена, её вполне можно было бы считать компьютером в рамках нашего определения.
 Небольшая часть «Аналитической машины», которую изобретатель успел завершить при жизни
Небольшая часть «Аналитической машины», которую изобретатель успел завершить при жизни
 Предполагаемый полный вид машины
Предполагаемый полный вид машины
То, что компьютер не появился в викторианской Англии, связано не только с ограничениями технологий того времени. В 1840-х годах человечество попросту не нуждалось в таком объёме расчётов, который могли обеспечить автоматические вычислительные машины. Только в XX веке с его атомным проектом и космической гонкой люди поняли, что им не обойтись без приборов, которые смогут расширить возможности их интеллекта.
На этом мы прикроем историческую лавочку и перейдём к другой интереснейшей теме — поговорим о том, почему компьютеры работают в двоичной системе счисления. Поехали!
Как компьютер выполняет программы
И почему он напрямую не работает с кодом, который пишет программист. А ещё — что общего у Терминатора и Бендера из «Футурамы»
Мы уже знаем, что главное отличие компьютеров от более примитивных вычислительных машин — возможность выполнять длинные цепочки вычислений в соответствии с программой.
Больше всех трудится процессор. Чтобы он мог выполнить программу, последовательность составляющих её команд сначала нужно записать в оперативную память.
С точки зрения процессора любая программа представляет собой последовательность команд в памяти. Просто берёшь и делаешь, раз-раз-раз.
Команда — требование к процессору выполнить операцию с данными.
Вспомним парочку важных вещей из предыдущих статей:
- Процессор считывает и команды, и данные из памяти.
- Память разбита на ячейки одинакового размера.
- К каждой ячейке памяти можно обратиться по её адресу.
Процессор любого компьютера может выполнять много разных операций. Среди них есть арифметические (сложение, умножение, деление), логические (сравнение, побитовое инвертирование — замена каждого бита в двоичном числе на противоположный), операции пересылки, операции управления и другие.
Непосредственным выполнением этих операций занимается блок процессора, называемый арифметико-логическим устройством (АЛУ).
Совокупность всех команд, которые может выполнять процессор, называют системой команд. Это важная характеристика процессора и компьютера в целом — она определяет, какие программы на нём заработают сразу, а какие придётся адаптировать. На заре компьютерных технологий каждая ЭВМ имела свою систему команд. О переносе программ между разными машинами можно было только мечтать.
Люди быстро поняли, что на адаптацию одних и тех же алгоритмов под разные системы уходит слишком много ресурсов, и потому уже начиная с 1950-х наметился курс на создание компьютеров, которые были бы совместимы между собой по системе команд. Это оказалось мудрым решением, и сегодня дела с переносимостью программ обстоят намного лучше.
Как выглядит команда
Рассмотрим для примера некую абстрактную ЭВМ — которая, впрочем, во многом похожа на реальные компьютеры начала цифровой эры. В этой ЭВМ все команды имеют одинаковую структуру:

КОП — это код операции, которую нужно выполнить. Например, 1 — сложение, 2 — вычитание, 3 — умножение и так далее.
А₁ — это адрес ячейки памяти, из которой нужно взять первый операнд. Операндом называют блок данных, который обрабатывают командой. Не путать с Орландо Блумом и Воландом.
А₂ — адрес ячейки, из которой нужно взять второй операнд.
А₃ — адрес ячейки, в которую нужно поместить результат операции.
Такие команды называют трёхадресными. Проводя аналогию со школьной задачей по математике, можно сказать, что КОП, А₁ и А₂ относятся к блоку «Дано», а А₃ — это уже «Ответ».
Для наглядности будем вместо кода операции писать её обозначение из нескольких заглавных букв: сложение — СЛЖ, вычитание — ВЧТ, умножение — УМН...
Адреса ячеек памяти будем записывать с нулём (012 вместо 12), чтобы отличать их от чисел, хранящихся в ячейках. Для удобства все значения будем давать в десятичной системе счисления — естественно, не забывая, что в компьютере они представлены в двоичном виде.
Всё просто, не правда ли? Впрочем, кого мы обманываем...
Для начала заполним память нашей воображаемой ЭВМ такими числами:

Теперь выполним команду СЛЖ 011 012 013. В АЛУ процессора поступят значения из ячеек с номерами 011 и 012 — числа 3 и 5. АЛУ выполнит их сложение и получит 8. Далее число 8 будет записано в ячейку с номером 013. В итоге содержимое памяти изменится:

Некоторые из адресов А₁, А₂, А₃ могут совпадать друг с другом. Например, если вы хотите увеличить содержимое ячейки А₁ на величину числа, записанного в А₂, то в поле А₃ вам нужно повторить А₁ — чтобы результат суммирования оказался в ячейке с адресом А₁.
СЛЖ 011 012 011
После выполнения команды память будет выглядеть так:

Более того, оказалось, что в реальных программах эти адреса совпадали довольно часто — например, если нужно было просуммировать множество чисел подряд. Поэтому почти одновременно с трёхадресными системами команд появились и более простые двухадресные.

Двухадресная команда может указывать, что результат операции нужно записать вместо одного из операндов. Поскольку у нас пока нет отдельного поля для выбора первого или второго операнда, мы можем ввести новые коды операций. Например, операция СЛ1 будет записывать результат на место первого операнда, а СЛ2 — на место второго.
СЛ2 011 012
В этом примере результат сложения окажется на месте второго операнда:

Наконец, есть немало процессоров с одноадресной системой команд!

А вот тут может быть непонятненько. Как с помощью одноадресной команды заставить компьютер сложить два числа, если можно указать только одно? Хитрость в том, что в одноадресных системах выполнение одной арифметической операции обычно требует нескольких команд. А в составе процессора есть узел, который называют регистром-аккумулятором.
Регистр — небольшое запоминающее устройство (как правило, на одно число или одну команду), которое входит в состав процессора и работает на одной скорости с ним.
Регистр-аккумулятор — регистр процессора, в котором сохраняются результаты выполнения арифметических и логических команд. Наличие такого регистра позволяет использовать одноадресные команды и в конечном счёте сделать процессор более простым.
Чтобы реализовать операцию сложения, нам придётся придумать несколько новых команд:
- ЗГР — загрузить содержимое ячейки памяти в регистр-аккумулятор. Эту операцию можно заменить операцией СЛА, если хочется.
- СЛА — сложить содержимое ячейки памяти с содержимым регистра-аккумулятора и записать результат операции в него же.
- СХР — сохранить содержимое регистра-аккумулятора в ячейке памяти по указанному адресу.
Вот так теперь будет выглядеть наша простейшая программа:
ЗГР 011
СЛА 012
СХР 013
Результат будет таким же, как в самом первом примере. За счёт увеличения количества команд и, пожалуй, некоторого снижения читаемости программы мы получили возможность уменьшить длину команд и упростить схему процессора.
Все примеры, показанные выше, очень простые. Но ни один из них не придуман только для иллюстрации: существовали компьютеры, команды которых выглядели именно так. Трёхадресные команды из примера 1 (КОП | А₁ | А₂ | А₃) использовались в вычислительной машине БЭСМ (1952).
 БЭСМ — классическая трёхадресная ЭВМ. Оператор мог по лампочкам на пульте видеть, какая команда выбрана из памяти и как она выполняется
БЭСМ — классическая трёхадресная ЭВМ. Оператор мог по лампочкам на пульте видеть, какая команда выбрана из памяти и как она выполняется
Двухадресные команды из второго примера (с несколькими дополнительными битами) использовала, например, ЭВМ «Минск-22» (1965). Одноадресные команды, эквивалентные приведённым в примере 3, были в системе команд первой массовой отечественной ЭВМ «Урал-1» (1957). Одноадресным был и первый советский суперкомпьютер БЭСМ-6 (1967), и многие другие машины.
В современных процессорах есть несколько регистров-аккумуляторов и другие специализированные регистры, а команды могут иметь переменную адресность.
Количество поддерживаемых команд сильно различается от процессора к процессору. Например, процессор «Урала-1» имел систему всего из 29 команд. Очень популярный в своё время микропроцессор MOS 6502 (он стоял в первых компьютерах Apple) мог выполнять 56 команд.
А ещё 6502 стоял, к примеру, в Терминаторе и Бендере из «Футурамы».
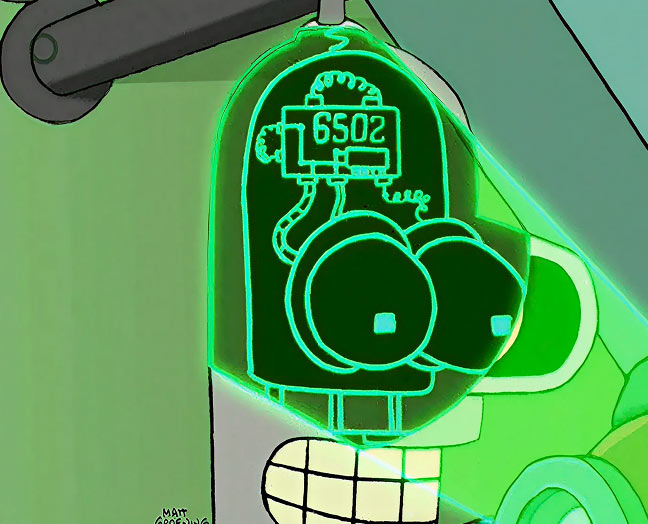 Фотодоказательство: процессор 6502 в голове робота Бендера Родригеса
Фотодоказательство: процессор 6502 в голове робота Бендера Родригеса
Современные процессоры с архитектурой x86-64 поддерживают свыше 800 разных команд. Одно только их описание в руководстве Intel занимает почти 3 тысячи страниц.
Понятно для человека — непонятно для компьютера
Когда мы записываем команду в виде СЛЖ 011 012 013, мы пользуемся буквами и десятичными цифрами. Но компьютеры, как мы знаем, на уровне аппаратуры работают только с двоичным кодом. Как будет выглядеть та же команда для процессора? Предположим, что на код операции у нас отводится 6 бит, а на каждый адрес — 11 бит (опять же, так было в БЭСМ). Заменяем, указывая в подстрочном индексе используемую систему счисления:
СЛЖ → 1₍₁₀₎ → 000001₍₂₎
Адрес 011₍₁₀₎ → 00000001011₍₂₎
Адрес 012₍₁₀₎ → 00000001100₍₂₎
Адрес 013₍₁₀₎ → 00000001101₍₂₎
То есть процессор видит нашу команду так:
000001000000010110000000110000000001101
Понятно? Для компьютера — абсолютно, а вот для нас — наверное, не очень. Да и, будем честны, в виде СЛЖ 011 012 013 команда тоже выглядит не вполне по-человечески. Люди всё-таки привыкли изъясняться на естественных языках, а компьютеру нужны однозначные инструкции, состоящие только из нулей и единиц. Здесь явно нужен «переводчик».
Поначалу в качестве таких переводчиков выступали сами программисты. Они составляли программы в удобном для себя виде, а затем переводили описание всех операций в машинный код.
Определение: машинный код — набор команд, специфичный для конкретной вычислительной машины, который интерпретируется непосредственно её процессором.
Далее технические сотрудники набивали этот код на перфокартах или перфоленте, и уже они поступали в устройство ввода ЭВМ.
 Оператор вводит данные с перфокарт в компьютер IBM 704, 1957
Оператор вводит данные с перфокарт в компьютер IBM 704, 1957
Это занимало очень много времени и требовало высочайшей квалификации программистов. Ситуация изменилась с появлением трансляторов — или, как их весьма точно называли в те годы, «программирующих программ». Программа-транслятор автоматически формировала машинный код на основе описания, составленного на специальном формальном языке — языке программирования.
Один из первых в мире трансляторов создали в СССР в 1954 году, он назывался ПП-1.
В современном IT процесс «перевода» с языка программирования на язык команд процессора называют компиляцией, а соответствующие программы — компиляторами. Так что, когда мы говорим о некой программе, нужно уточнять, что именно мы имеем в виду — её исходный код или уже исполняемый файл:
- Исходный код — это изначальный текст на языке программирования, составленный человеком (или искусственным интеллектом).
- Исполняемый файл, он же «бинарник», — это скомпилированный код, который может быть выполнен компьютером.
Первый массовый язык программирования высокого уровня — Фортран, 1957 (сокращение английского Formula Translator). Изначально он был разработан для компьютера IBM 704. Продолжает развиваться до сегодняшнего дня и довольно широко используется в научных расчётах.
В качестве промежуточного звена между языком высокого уровня и машинным кодом можно выделить так называемый язык ассемблера. Он максимально близок к машинному коду того или иного процессора, но позволяет вместо нолей и единиц использовать понятные мнемоники для названий команд, регистров, а также обращаться к переменным по именам.
Примеры для СЛЖ 011 012 вполне могут считаться командами на языке ассемблера некого абстрактного процессора. Реальная ассемблерная команда может выглядеть, например, как ADD AX, BX. Процессор сложит содержимое регистра AX с содержимым регистра BX и запишет результат в AX.
Язык ассемблера незаменим, когда нужно максимально точно «объяснить» процессору, как именно он должен решать задачу, — например, если компилятор выдаёт неэффективный, избыточный код.
Создание языков высокого уровня значительно повысило скорость и удобство разработки программ и позволило привлечь в программирование много людей, не являющихся профессиональными математиками и инженерами. Со временем появление ещё более дружелюбных к новичкам языков открыло доступ в мир программирования даже для детей, едва научившихся читать и писать.
Ну а наша следующая остановочка — «Что происходит в компьютере, когда вы нажимаете на кнопку».
Что происходит в компьютере, когда вы нажимаете на клавишу
За одну секунду в компьютере происходит столько разных процессов, о которых мы не знаем! Но совсем скоро узнаем, даже прямо сейчас
Эта статья отличается от тех, что вы читали ранее: речь пойдёт о современном компьютере — со всеми усовершенствованиями и доработками, которые были сделаны за последние 70–80 лет. Ну наконец-то!
А говорить будем о действии, которое многие повторяют тысячи раз на дню, — нажатие клавиши на клавиатуре. Итак...
01
Вы нажимаете на клавишу. Она плавно опускается, оказывая сопротивление пальцу. За это отвечает пружина (в механических клавиатурах) либо купол из упругого силикона (в мембранных).

02
Два электрических контакта под этой клавишей замыкаются. Возникает проводимость между дорожками внутри клавиатуры.
03
Основываясь на том, какие именно контакты были замкнуты, микроконтроллер внутри клавиатуры определяет, что за клавиша была нажата. Дорожки на клавиатуре можно рассматривать как матрицу из строк и столбцов, выводы которых соединены с ножками микросхемы контроллера. Подавая напряжение на одну из ножек и определяя, на какой ещё ножке при этом повысилось напряжение, контроллер выясняет, на пересечении какой строки и какого столбца находится нажатая клавиша.
Примерно как в игре «Морской бой»: «Б-4! — Ранил!»
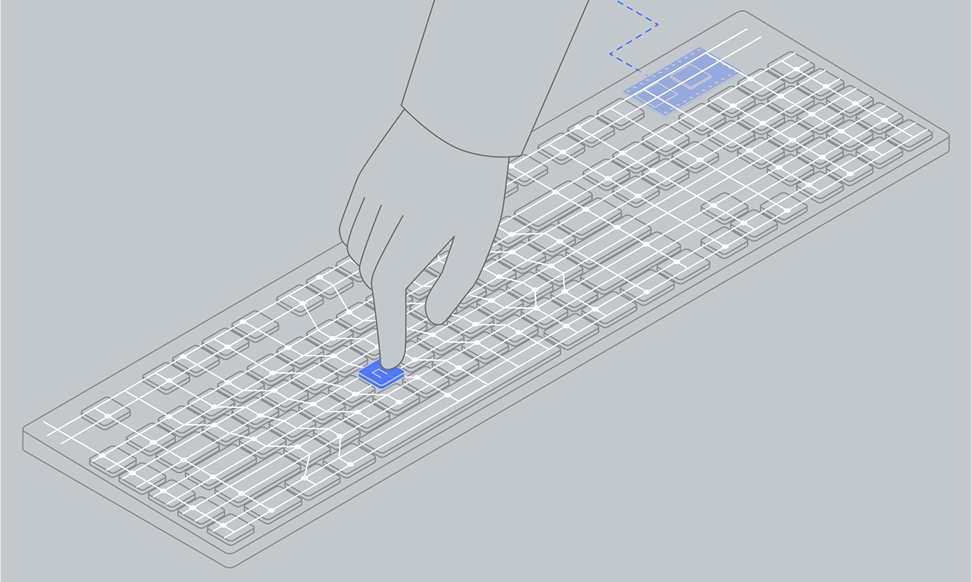
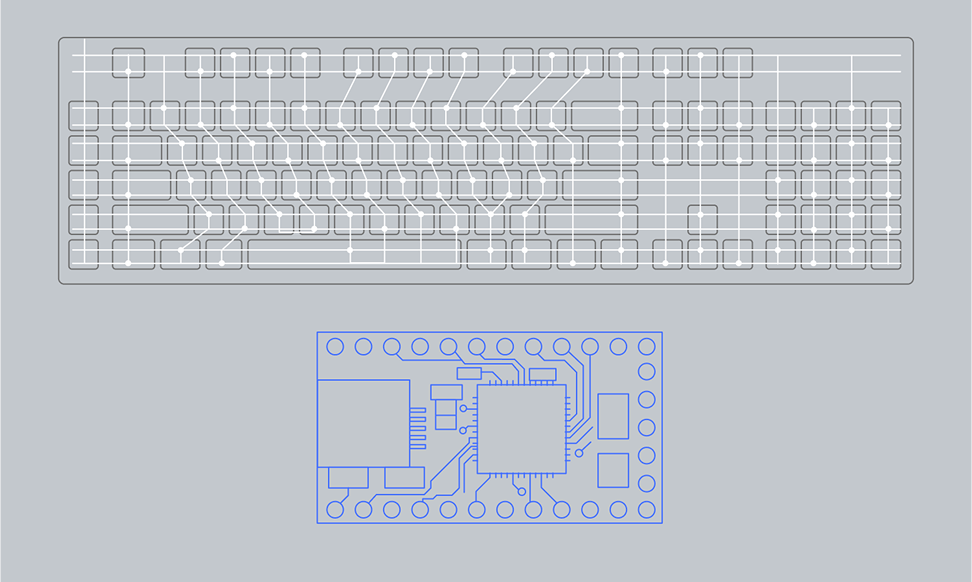
04
Микроконтроллер клавиатуры обращается к своей постоянной памяти, в которой хранятся комбинации нулей и единиц, соответствующие всем клавишам, — так называемые скан-коды. Далее он посылает этот код контроллеру периферийного интерфейса, через который клавиатура подключена к компьютеру. В современных компьютерах это интерфейс USB, а раньше мог использоваться, например, PS/2.
05
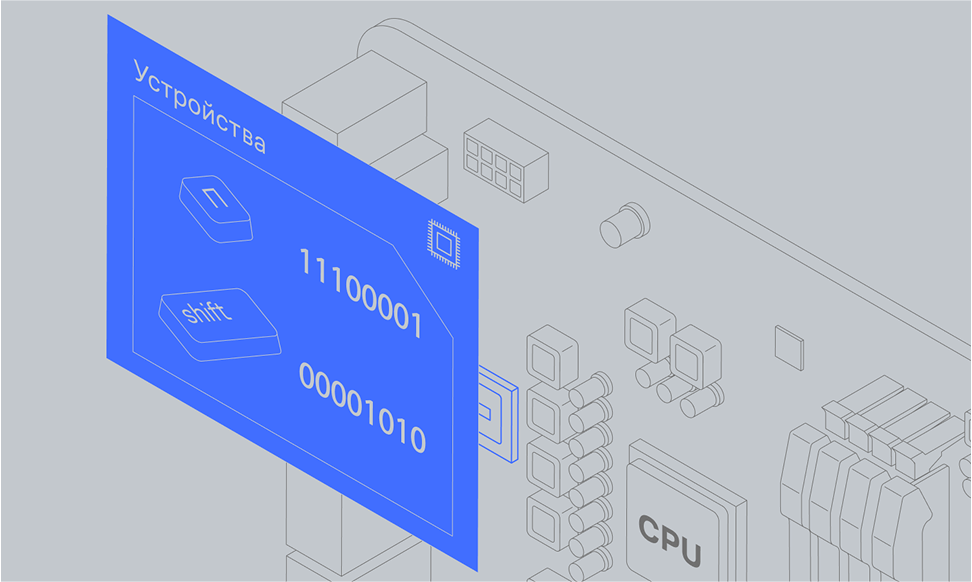
Контроллер интерфейса USB принимает данные, поступившие от клавиатуры, и записывает их в свою память. В ней также может храниться информация о предыдущих нажатиях — например, если ранее вы зажали клавишу Shift, чтобы буква получилась заглавной.
Сигнал c кодом клавиши — 00001010 — «течёт» по проводу от микроконтроллера клавиатуры к контроллеру на материнской плате компьютера.
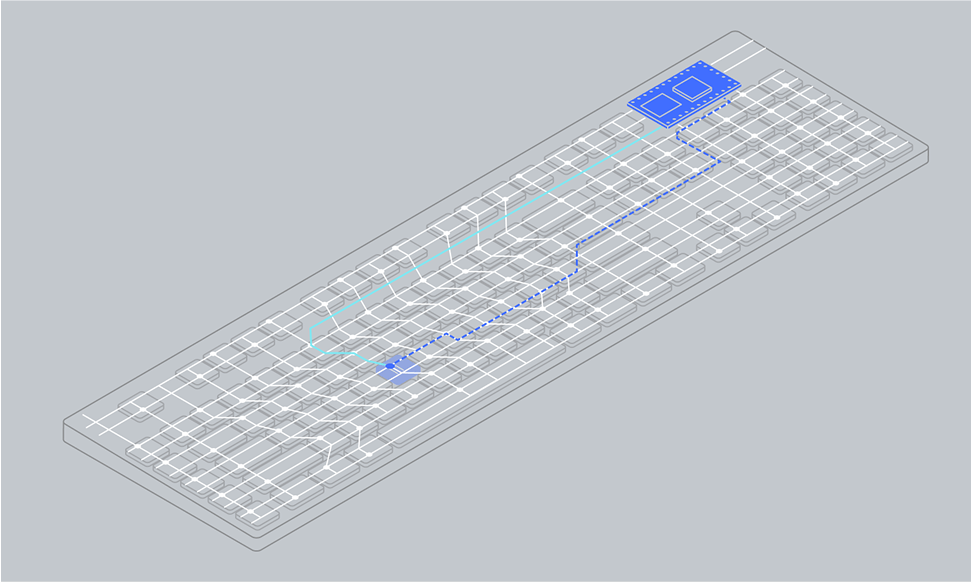
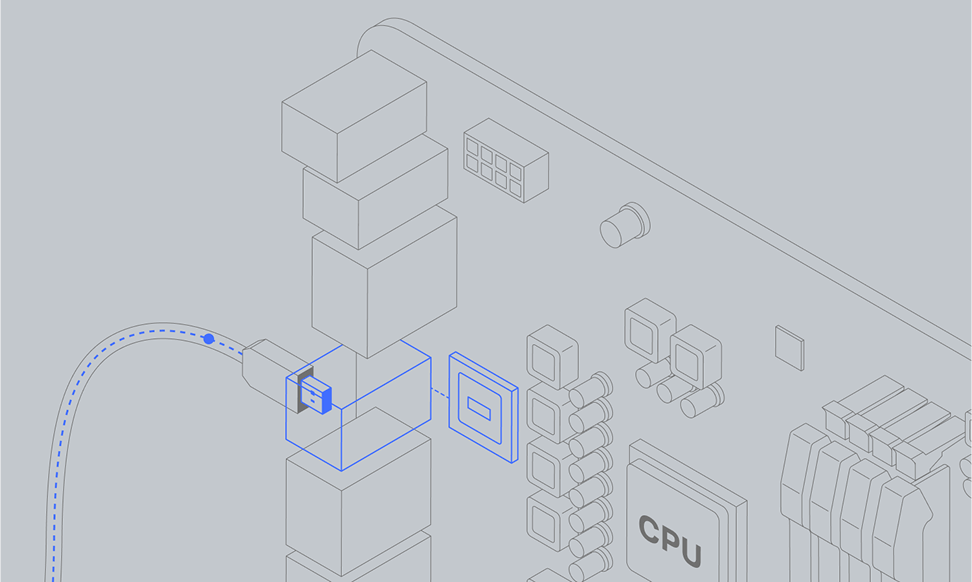
06
Контроллер интерфейса USB отправляет сигнал о поступлении новых данных, который проходит через чипсет — основной набор микросхем на материнской плате — к контроллеру прерываний. Ранее это могла быть отдельная микросхема, называемая PIC (Programmable Interrupt Controller), но в современных системах это небольшой модуль внутри центрального процессора.
07
Процессор получает сигнал от контроллера интерфейса.
Скорее всего, какое-то время он будет его игнорировать, поскольку сейчас он занят более важными задачами. Но для человека это слишком короткая задержка, чтобы её можно было заметить.
Далее процессор запускает специальную программу для обработки события «нажатие клавиши на клавиатуре». На время работы этой программы он прерывает выполнение других программ, поэтому такие сигналы и называют прерываниями.
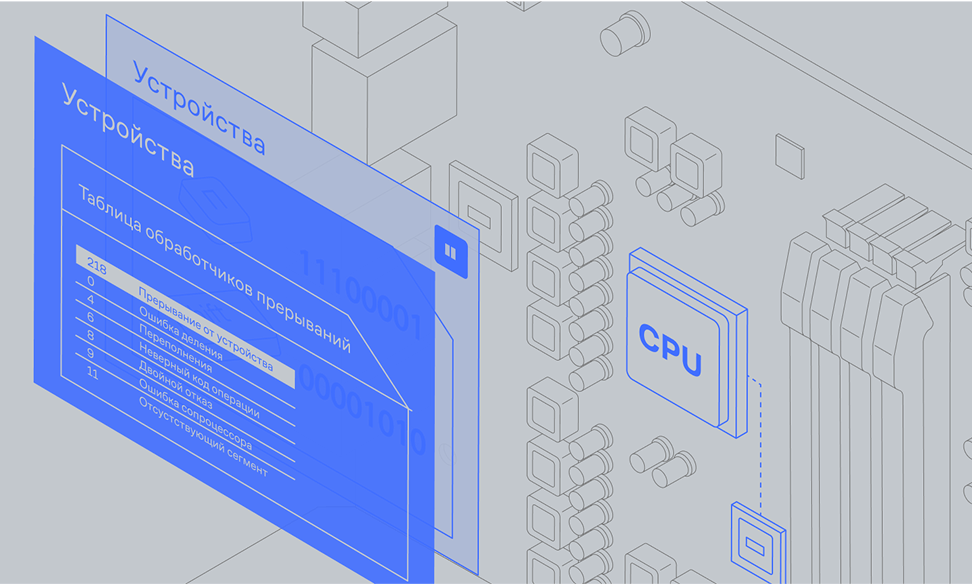
08
В операционной системе (ОС) регистрируется событие «нажатие клавиши на клавиатуре». ОС уведомляет об этом программы, которые «подписаны» на такого рода события, в том числе ту, чьё окно сейчас активно, — например, мессенджер.
09
Программа-мессенджер обрабатывает поступившее событие. Она добавляет в свою область памяти информацию о дополнительном символе в окне для набора сообщений. Теперь ей нужно отобразить этот символ шрифтом определённого начертания и размера. Для этого она направляет запрос к графической подсистеме компьютера.
10
Происходит обращение к графическим библиотекам DirectX/OpenGL. С их помощью, опираясь на имеющееся в системе описание символов шрифта, графическая подсистема определяет, как должна выглядеть нажатая буква в окне нашей программы.
11
Теперь на основе данных от графической подсистемы нужно составить инструкции для графического процессора (GPU), который будет непосредственно выполнять «рисование» буквы. За составление таких инструкций отвечает видеодрайвер. Он обладает информацией об устройстве конкретной видеокарты, которая установлена в компьютере.
12
Инструкции от драйвера видеокарты передаются контроллеру интерфейса, к которому подключена видеокарта. В современных компьютерах это интерфейс PCI Express, ранее мог использоваться AGP или PCI. Контроллеры высокоскоростных интерфейсов сегодня обычно встроены в центральный процессор, а в прошлом они обычно были частью чипсета на материнской плате. В соответствии с правилами работы интерфейса контроллер преобразует инструкции в последовательность электрических сигналов, и те, дождавшись своей очереди, отправляются на видеокарту.

13
GPU декодирует полученные инструкции, выполняет расчёты и сохраняет в памяти видеокарты набор чисел, соответствующих нужным пикселям в определённом месте экрана.
14
Когда наступает момент очередного обновления экрана (это происходит с частотой 60–144 раза в секунду), видеокарта превращает набор чисел из своей памяти в сигнал, который отправляется на монитор по одному из доступных интерфейсов — например, DisplayPort или HDMI. В более старых системах это мог быть цифровой интерфейс DVI или аналоговый VGA.
15
У монитора тоже есть свой микроконтроллер. Он анализирует данные об изображении, полученные от видеокарты, соотносит их с физическим разрешением матрицы и понимает, какие именно пиксели нужно зажечь и погасить, чтобы сформировать требуемую картинку.
16
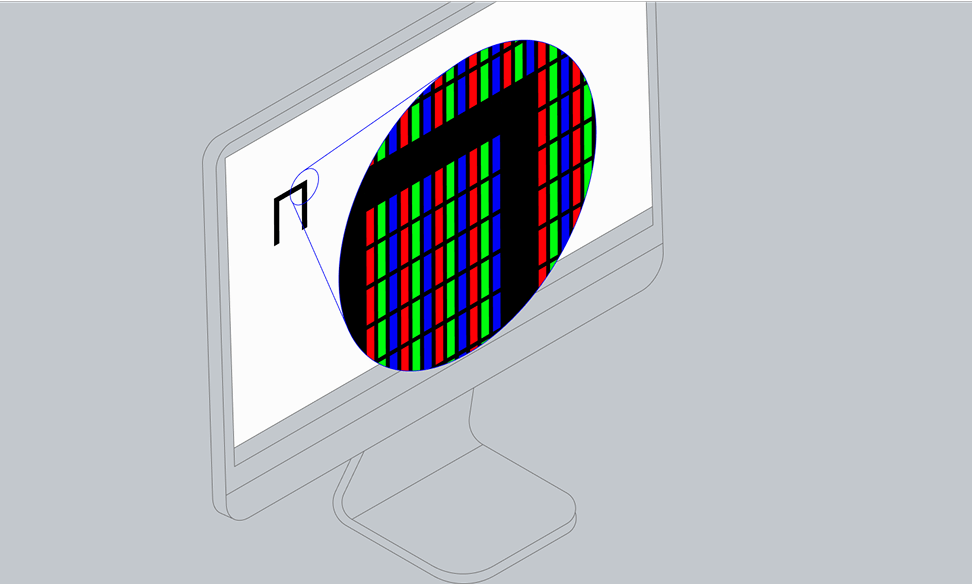
Если мы говорим о жидкокристаллическом мониторе (ЖК), то его матрица состоит из миллионов пикселей, каждый из которых, в свою очередь, состоит из трёх субпикселей, закрытых светофильтрами трёх базовых цветов — красного, зелёного и синего. Внутри ячейки каждого субпикселя находятся жидкие кристаллы. Под воздействием приложенного к ним электрического напряжения они поворачиваются на определённый угол — и за счёт поляризационного фильтра меняется их прозрачность.
17
Ровный белый свет от подсветки монитора (светодиодной или на лампах), проходя через частично прозрачные субпиксели и цветные фильтры, формирует изображение, состоящее из миллионов цветных точек. Пользователь видит, как в окне мессенджера появилась только что нажатая им буква.
Конец!
Как видите, за элементарным действием, результат которого мы наблюдаем на экране через считаные миллисекунды, стоит множество сложных процессов. На самом деле даже это длинное описание — очень упрощённое, а некоторые шаги мы намеренно пропустили. Одно только описание правил работы каждого из упомянутых в статье интерфейсов занимает несколько десятков, а то и сотен страниц в технической документации.
Как хорошо, что читать эту документацию приходится только программистам (да и то в редких случаях). Кстати, о программистах: о них наша следующая статья!
Операционные системы: какими они бывают и как они устроены
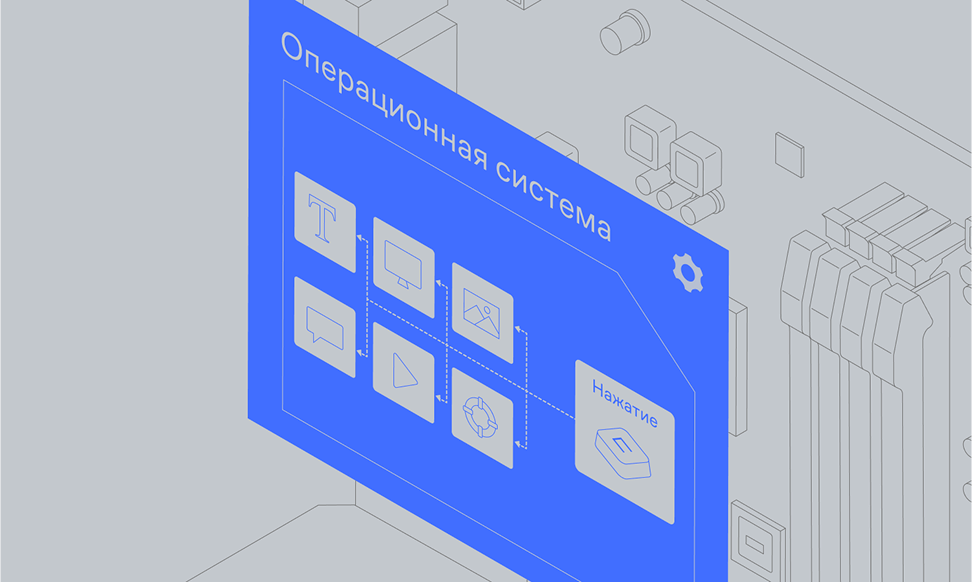
Windows, macOS, Android, iOS — знакомые всем слова. Но что такое операционная система сама по себе? «То, что управляет компьютером, чтобы там всё работало»? Хороший ответ, но у него есть недостаток: он не даёт понимания, что же это такое. Ну что, давайте разберёмся!
Чем вообще занимается операционная система?
Сам по себе любой компьютер — это набор «железа», простых логических элементов, собранных и сгруппированных для выполнения конкретных задач.
Процессор производит вычисления, жёсткий диск хранит информацию, а Wi-Fi-модуль общается с сетью. Чтобы это железо было доступно пользователю, нужна прослойка, которая умеет с этим железом «общаться» и приводить всё в удобный для пользователя вид.
Нас не интересует, как на жёстком диске расположен ваш файл, мы просто хотим открыть сериал и посмотреть его. Именно эти задачи и берёт на себя операционная система. А ещё — самую необходимую для пользователя функцию: запускать программы и следить за их исполнением.
А какими они вообще бывают?
Кроме четырёх самых известных и популярных, операционные системы есть почти в каждом сложном современном устройстве. Умные часы, принтер, Алиса, табло в автобусе, автомобили (и медиасистема в них), домашний роутер и даже счётчики воды, умеющие передавать показания...
Так что полезно различать классы операционных систем. Среди них выделяют Windows, *nix и прочие операционные системы (с которыми обычный человек в нормальной жизни не сталкивается).
Самые простые — это Windows. В их числе и знакомые всем версии 7, 10 и 11, и серверные варианты, называемые просто Windows Server, и ушедшая с рынка Windows Mobile, точнее Windows CE, и редкая Windows Embedded для промышленных устройств, а ещё Xbox System Software (да, на игровой консоли от Microsoft тоже стоит Windows, хотя и очень специфическая).
Все эти варианты Windows довольно сильно отличаются друг от друга — в зависимости от задач, для которых они сделаны.
Так же будет с классами систем *nix (это общее название для всех операционных систем, которые пошли из общего корня Unix многие десятилетия назад). Самые известные из них в наше время — это Linux, Android и macOS. Хотя у всех трёх общий предок, теперь уже непонятно, насколько они близки к оригиналу: это как корабль Тесея.
Корабль Тесея — философский парадокс, основанный на легенде о корабле, который постоянно ремонтировали. Когда в корабле поменяли каждую доску и каждый гвоздь, остался ли корабль тем же самым?
Много лет назад Apple взяла один из вариантов Unix и доработала его до операционных систем macOS и iOS, которые теперь используются в Макбуках и Айфонах.
Linux же появилась как ответ на платный Unix — и, хотя базировалась на похожих принципах, была открытой и бесплатной, что привело к появлению вокруг неё большого сообщества единомышленников.
В итоге она породила тысячи (если не десятки тысяч) разных версий операционной системы — благодаря своей модульности.
В том числе Linux стала основой, на которой сделали Android.
Также надо упомянуть, что студенты в институтах пишут очень много простых миниатюрных операционных систем: например, есть целый курс «Проектирование операционных систем». Много небольших операционных систем и в микроконтроллерах, на которых основаны элементы «умного дома». Обычно у таких систем нет названий — или они совпадают с названием вещи или бренда.
Ну хорошо. А из чего состоит операционная система?
Операционную систему принято делить на ядро, системные библиотеки, оболочку и утилиты:
- Ядро содержит в себе все нужные драйверы и понимает, как работать с железом. Также в нём есть всё, что касается управления оперативной памятью и программами.
- Системные библиотеки — это набор программ, обеспечивающий «общение» всего, что запущено на компьютере, с ядром.
- Оболочка — это обычно интерфейс, который операционная система предоставляет пользователю для взаимодействия с собой. Например, рабочий стол в Windows и macOS.
- Утилиты — это готовые программы-инструменты, которые операционная система предлагает для удобства работы пользователя. Трудно представить себе Windows без «Проводника» или macOS без Finder. Но на самом деле их может и не быть, работе самой системы это не помешает.
Как это всё вообще работает?
Когда вы включаете компьютер, операционная система просыпается и начинает работу. Сначала она проверяет, всё ли в порядке с железом, затем загружает ядро, драйверы и, наконец, показывает вам рабочий стол. Каждый ваш клик мышкой или нажатие клавиши — это запрос к ОС, которая решает, как его обработать.
Когда пользователь захочет открыть папку с картинками, проводник спросит у ядра: «А что у нас по этому пути?» И ядро пнёт драйвер жёсткого диска с тем же вопросом.
Драйвер скажет: «Не буду читать диск, у меня тут в кеше данные есть, держи», — и всё это вернётся обратно. Проводник на это посмотрит, скажет: «Тут картинки, нужны превью», — и ядро пойдёт доставать превью картинок из кеша системы, чтобы всё это красиво отобразить.
Если пользователь захочет запустить программу, ядро пойдёт проверять, может ли оно исполнить код, который там написан, и есть ли свободная память, чтобы добавить туда ещё одну программу. Затем начнёт выполнять её и отвечать на запросы программы вроде «А дай мне из такой-то библиотеки то-то».
А для чего нужны драйверы и службы?
Если очень просто, драйверы — это специальные программы, которые знают, как правильно общаться с устройствами в рамках конкретной операционной системы. Потому что обращаться напрямую к железу, в обход ядра, операционная система не разрешит. А им надо уживаться вместе, так что каждый драйвер знает, что спрашивать и как отвечать операционной системе на соответствующие запросы.
Службы — это небольшие программы, выполняющие определённые функции. Например, служба, которая синхронизирует время, иногда запрашивает из интернета данные о времени, сверяет полученное с системными часами и, если есть расхождение, обновляет время.
В *nix-системах службы называются демонами.
А служба Plug and Play иногда спрашивает ядро: «У нас ничего нового из железа не появилось?» И если появилось, пытается инициализировать устройство — чтобы, когда вы втыкаете флешку, она сразу отобразилась в «Проводнике».
Расскажите про оболочки операционной системы!
Строго говоря, рабочий стол в Windows или домашний экран Android — это не часть операционной системы, а программа, которая поставляется дополнительно. Но все настолько привыкли к этим элементам, что их обычно включают в состав операционной системы под названием «оболочка».
Оболочки бывают и в виде простой консоли: чёрный экран, белый текст на нём — и всё. Но и это тоже оболочка операционной системы.
Первые операционки были совсем другими?
В середине прошлого века компьютеры работали иначе, чем привычные нам сегодня. Проще всего их сравнить с громадными программируемыми калькуляторами, они использовались для вычислений. Управление логикой таких компьютеров было целиком основано на схемотехнике.
Компьютеры тех лет создавались для выполнения одной программы. Чтобы заставить такой компьютер считать другое уравнение, надо было брать паяльник и перепаивать плату. Некоторые можно было перенастроить перемычками и тумблерами, но это всё равно было долго и сложно.
А человек всегда стремится к оптимизации работы, так что Роберт Патрик и Оуэн Мок придумали систему, которая позволяла выполнять следующую программу, когда прошлая заканчивалась. Их разработка следила за очередью программ, которую сформировал программист. А из описания программы можно было частично управлять логикой происходящего внутри, например выбирать, какие результаты напечатать. Сейчас это кажется очевидным, но тогда это было весьма инновационно. Этот момент в 1955 году и принято считать началом операционных систем.
Операционная система Роберта Патрика и Оуэна Мока называлась GM-NAA I/O. Если название кажется вам странным, то знайте, что это просто аббревиатура от General Motors & North American Aviation Input/Output system, создатели работали в General Motors и North American Aviation соответственно.
Получается, первая операционная система в мире, если убрать названия компаний, называлась «система ввода и вывода». Впрочем, тогда операционным системам не требовались звучные названия.
А когда появились более привычные операционные системы?
В 1964 году вышла Multics авторства General Electrics и Bell Labs. Её стоит упомянуть из-за концепции файловой системы с деревом папок, знакомой нам до сих пор. А в 1969 та же Bell Labs выпустила первую Unix, которая, ко всему прочему, умела работать с сетью и подключаться к другим компьютерам. Обе системы, как могли на тот момент, реализовывали многозадачность, но это было не очень востребовано. Системы ещё не были приятны и удобны для пользователя, их оболочкой был командный интерпретатор — та самая чёрная консоль с белым текстом.
Перенесёмся в 1973 год, когда компания Xerox создала свою операционную систему Alto OS. Она была уже отдалённо похожа на то, что нам знакомо: там был прототип рабочего стола, графическая оболочка и окна для просмотра файлов.
К сожалению, система сильно опередила своё время: компьютер, который это мог тянуть, стоил очень дорого, а необходимая для работы мышка вызывала у всех вопрос «Что это и зачем?» — и осталась скорее прототипом.
Зато, посмотрев на эту операционную систему, один студент подумал: «А чем я хуже?» Этого студента звали Билл Гейтс.
Так появилась Microsoft. Сперва компания занималась программным обеспечением, а к операционной системе приступила по заказу IBM, перекупив чужие наработки. Так или иначе, сначала на свет появилась MS-DOS, а потом и первая Windows — которая с треском провалилась: она требовала очень много ресурсов, была надстройкой над MS-DOS и никто снова не понял, для чего всё это нужно.
Параллельно с этим Стив Джобс, также насмотревшись на Alto OS, решил сделать свою операционную систему с графическим интерфейсом и мышкой. Он дал ей имя своей дочери — Lisa. Проект был не очень удачным, новая система тоже оказалась очень дорогой, но это позволило Джобсу договориться с Xerox и забрать себе часть наработок. И у него возникла грандиозная идея, что в операционной системе должен быть отзывчивый и приятный пользователю интерфейс. Так появились первые Маки, они же Macintosh, с куда более дружественной графической оболочкой. Вот тогда всё и закрутилось.
Давайте ближе к нашему времени!
В конце 80-х и начале 90-х годов операционных систем было много, как и типов, и архитектур компьютеров. Каждая крупная технологическая компания пыталась сделать что-то своё, но гонку выиграла IBM и те, кто вступили с ней в альянс, начав выпускать компьютеры на основе Intel-чипов.
Упомянем OS/2, к которой тоже приложила руку Microsoft. Сначала это должна была быть альтернатива MS-DOS для IBM PC, но в итоге она уступила Windows, особенно после выхода версии 3.0. Долгое время OS/2 была довольно популярна как серверная система для Java-приложений, но сейчас её проще увидеть в музее.
Microsoft выпустила свой вариант серверной операционной системы, Windows NT (сокращение от New Technology), которая была действительно технологически продвинутой.
Другая ОС, Novell Netware от компании Novell, была сразу ориентирована на работу с сетью и долгое время считалась эталоном быстродействия для операционной системы. Её пятая версия была одной из первых коммерчески успешных систем, которая научилась запускать сомнительные приложения в защищённом пространстве памяти, чтобы снизить потенциальный вред от вирусов. Эту методологию переняли и другие системы, позже это стало стандартом.
Тогда же появляется Linux — и сразу привлекает энтузиастов из-за своей открытости и бесплатности.
А если чуть дальше, к концу 90-х?
Windows задавила почти всех конкурентов, став стандартом для персональных компьютеров.
Но тут Стив Джобс вернулся в Apple и нанёс ответный удар, обвинив Билла Гейтса в краже части кода их операционной системы для создания своей. Всё это подкреплялось иском на миллиард долларов.
В итоге компании договорились, Microsoft вернула поддержку своих продуктов для компьютеров Apple, что позволило последним вернуться на рынок.
Тогда же выходит потрясающая BeOS для компьютеров на архитектуре PowerPC. Она навсегда останется в сердцах тех, кто её видел, благодаря привлекательности рабочего стола и окружения.
Тут же стоит упомянуть появление мобильных операционных систем. Первые Palm OS, Newton OS от Apple — да, Apple выпускала планшеты со своей ОС ещё в 1993 году, а вы не знали? Compaq выпустила планшет на основе MS-DOS и Windows 3.11 с поддержкой стилуса и экраном Wacom. Вышла Series 20 от Nokia (именную ОС они сразу назвали с числом 20). Почти все такие системы были встроенными, то есть проектировались под конкретные устройства и чипы.
Ну а дальше — уже новая эра операционных систем?
В нулевые годы пользователи Linux задумались о том, что можно сидеть не только в консоли, и это семейство операционных систем приобрело довольно приятный для обычного пользователя оконный менеджер и общий визуал. Начинает появляться много вариантов Linux-систем, в том числе с разными преднастроенными графическими оболочками.
В какой-то момент высшей точкой этого подхода стал мем «нескучные обои», подразумевающий очередной вариант Debian (а скорее всего — Ubuntu, так как её проще всего пересобрать): сборки Linux, в которой от оригинала отличаются только обои и цвет окон по умолчанию. Но стоит отметить, что многие долгоживущие сборки Linux действительно серьёзно отличаются друг от друга.
Среди настольных операционных систем также продолжала развиваться Windows: вышла легендарная XP, потом не очень успешная Vista, после которой — семёрка, снова удачная.
Apple в это время усердно переделывала свои ноутбуки и компьютеры — и очень сильно проапгрейдила macOS, завоевав немало сердец пользователей по всему миру.
Но главное случилось в июне 2007 года, когда Стив Джобс вышел на сцену и показал миру первый iPhone, у которого была новая операционная система — iOS. Тут надо сразу сделать ремарку: носимые карманные компьютеры, или КПК, были распространены задолго до этого — и там отлично чувствовали себя Palm OS, Windows Mobile и Blackberry OS. К ним добавлялось много вариантов Symbian, которые были на всех сотовых телефонах с поддержкой Java. Но общая маркетинговая стратегия Apple принесла Айфонам успех, и iOS широко распространилась, перейдя потом на планшеты и карманные музыкальные плееры от всё той же Apple.
А за несколько лет до этого пара энтузиастов создала свою операционную систему для цифровых камер. Первая версия называлась Fadden Demo.
Потом они подумали, что цифровые камеры — это как-то мелко, и захотели сделать что-то для сотовых телефонов, чтобы подвинуть Symbian и Windows на рынке. Один из авторов вспомнил, что у него есть красивый домен android.com, и решил переименовать компанию и операционную систему в Android. Их купила Google, а что было дальше, вы и так знаете: в 2008 выходит HTC Dream — и с тех пор Android на каждом втором телефоне в мире!
Ну и вот мы пришли... в наши дни?
В наши дни на персональном компьютере чаще всего установлена Windows, macOS или Linux. Иногда недорогие компьютеры поставляются с MS-DOS, но эта операционная система используется как заглушка, чтобы пользователь сам поставил то, что ему необходимо.
Есть ещё довольно редкая Chrome OS, операционная система от Google, построенная вокруг их браузера и веб-приложений. Если посмотреть чуть шире и обратить внимание на серверы и промышленное оборудование, то в список добавится Unix, чаще всего представленный RedHat и FreeBSD, но там в основном доминирует Linux.
А сегмент операционных систем для встроенного оборудования зачастую не имеет определённых названий. Например, умная колонка от Google работает на модифицированной версии ChromeCast, так же называется их ТВ-приставка. А у Яндекс-станции операционная система носит лаконичное название YaOS X.
Ну а мы с вами движемся дальше!
Что такое файловая система
И почему, если извлечь флешку сразу после копирования, на ней может не быть файла
Файловые системы — это системы организации хранения файлов и папок на диске. Понимание того, как они устроены, часто помогает в разработке и отладке программ. Но не только!
Как компьютер хранит данные
Любой жёсткий диск — это набор хранимых битов информации, единиц и нулей, объединённых в блоки по 8 бит, образующие байты. SSD или флешки используют много-много специальных транзисторов, которые хранят заданное значение очень долго, даже обесточенные.
Эти транзисторы умеют хранить двоичное значение, 0 или 1, это и есть бит информации. А на пластины классических крутящихся дисков нанесён ферромагнитный сплав, на каждом из участков которого может быть установлен заряд — и позднее прочитан. Редкие в наше время дискеты, CD, DVD и магнитные ленты работают по схожему принципу, просто механизм записи и чтения у них иной.
Важно знать, что на уровне самого жёсткого диска нет никаких файлов или каталогов, есть только каша из нулей и единиц — и всё!
У жёстких дисков есть контроллер, с которым операционная система общается через драйвер. Когда вы открываете файл с фильмом, она говорит драйверу: «Сместись на несколько ячеек и прочитай мне такой-то адрес».
Если у вас диск объёмом 1 ТБ, он хранит примерно 10¹² байт. А чтобы прочитать файл длиной 4 КБ (то есть 4096 байт) откуда-то из середины диска, операционная система попросит: «Прочитай мне данные с места 5 000 000 000 000 по 5 000 000 004 095». И жёсткий диск вернёт как раз 4096 байт информации. Но на уровне драйвера жёсткого диска тоже нет никаких файлов и каталогов...
При чём тут файловая система
Файловая система появилась, потому что кашу из информации надо подписывать, класть в папки и раздавать права, указывая, кто эти файлы может читать, а кто нет. Общие принципы организации разных типов файловых систем похожи, рассмотрим сначала их, а потом погрузимся в нюансы.
На диске есть небольшая область, где собрана информация о разделах диска, — таблица разделов. Она хранит данные о том, где каждый раздел начинается и заканчивается. Именно за счёт неё можно поделить один физический диск на разделы (partition).
То есть пустой раздел диска — это область, где по мере сохранения файлов у нас будет записана информация обо всех файлах и много пустого места.
Представьте себе хорошо знакомый лист в клеточку. Наверху мы напишем, в какой части листа у нас какой раздел, а потом разделим его на зоны. Каждая такая зона будет отдельным разделом. В одной части листа мы будем писать заметки, в другой — рисовать графики, а сверху у нас будет описание, какая зона для чего предназначена.
Всё место внутри раздела делится на блоки (а для старых крутящихся дисков — на сектора). Это небольшие отрезки размером в несколько килобайт (пропорционально размеру диска, для привычных нам дисков в 0,5–10 ТБ один блок или сектор обычно будет 4 КБ), которые выделяются для хранения каждого файла.
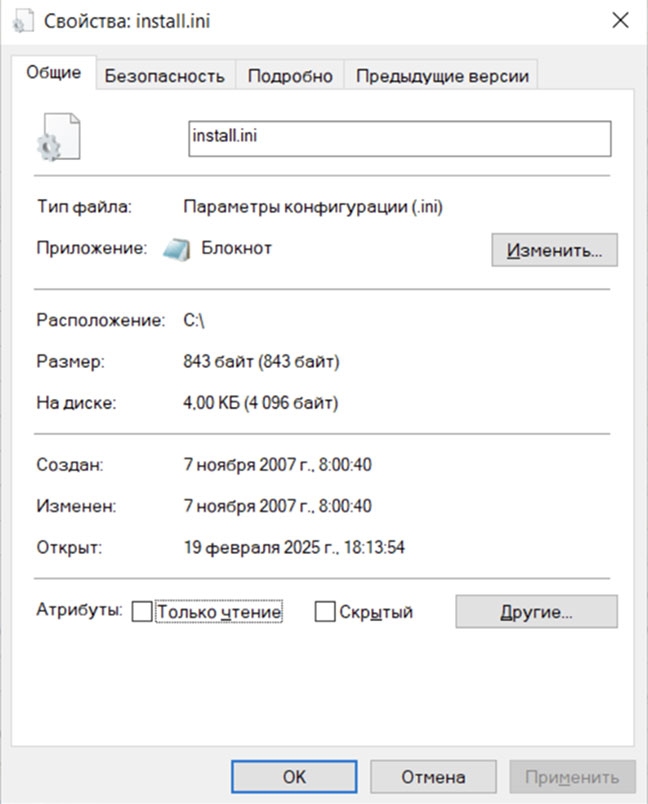 Файл размером 842 байта занимает на диске 4 КБ. Это как раз один блок
Файл размером 842 байта занимает на диске 4 КБ. Это как раз один блок
Когда мы создаём файл, драйвер диска находит свободное место для него, записывает себе адрес этого файла на диске в табличку и сохраняет. Теперь мы знаем, в каком блоке диска искать этот файл. Если наш файл размером больше одного блока, файловая система находит свободный блок на диске, записывает туда один из блоков файла, а когда закончится первый блок — находит следующий и пишет туда, пока вся информация не будет записана. Информацию, где позже искать блоки, система сохраняет в табличку со сведениями обо всех файлах.
Вернёмся к нашему листочку. Каждая клетка будет соответствовать одному блоку. Если нам надо записать цифру, мы поместим её в одну клетку, а если надо написать предложение, оно займёт несколько клеток. Запись предложения наверняка будет занимать все свободные клетки подряд: например, половина первого слова влезает в две клетки, после мы пропустим несколько уже занятых клеток и допишем остаток предложения в свободные.
Например, у нас есть файл размером в 2,5 блока, то есть 10 КБ. Диск у нас более или менее заполнен, так что, когда мы сохраняем файл, может получиться, что он сохранён в блоки 212, 213 и 20 517. Да, два первых блока идут рядом, а третий где-то далеко от них. Но файловая система знает, где их искать, так что, когда нам потребуется прочитать этот файл, мы прочитаем его весь.
С папками всё ещё проще. Сама по себе папка ничего не весит, это всего лишь способ группировать наши файлы, так что, создавая папку, мы указываем в табличке с информацией, что файлы лежат в такой-то папке.
Интересная вещь происходит, когда мы удаляем файл. Мы помним, что файл у нас — это и запись в табличке, где его искать, и номера блоков, где он лежит. Так вот, когда мы удаляем файл, мы стираем указатель в табличке, а система считает выбранную последовательность блоков свободной. Когда мы будем сохранять какой-то другой файл, система может разместить его в том же месте.
Зная информацию из удалённых файлов, мы можем попытаться найти и восстановить содержимое блоков на диске. Так устроено низкоуровневое восстановление данных.
Ещё стоит упомянуть, что и драйвер диска, и контроллер очень любят все оптимизировать. Например, вы переносите файл с одного диска на другой, а конечный диск занят чем-то ещё. В таком случае часть файла может остаться в оперативной памяти компьютера или контроллера диска — и через какое-то время (обычно небольшое) эти данные будут записаны на диск. Это сильно ускоряет работу системы, но часто приводит к неприятным последствиям.
Когда окно со статусом копирования исчезло, вам кажется, что система уже скопировала файл. Вы выдёргиваете флешку, но потом обнаруживаете, что файл не читается или отсутствует.
Твердотельные диски любят оптимизировать хранение файлов, не последовательно записывая данные, а распределяя их по реже использовавшимся ячейкам. Это связано с тем, что используемая в них память имеет большой, но ограниченный ресурс перезаписи. И если постоянно перезаписывать ячейки диска в начале, не трогая остальные, то они первыми исчерпают ресурс.
А более старые, крутящиеся диски умели сами находить повреждённые сектора на своих пластинах. Они отмечали у себя в контроллере, что этот сектор больше не работает, и сами перемещали данные из них в исправные участки. Это приводило к тому, что со временем диск начинал работать медленнее и у него уменьшался доступный объём.
Как хранение данных связано с операционной системой
А теперь поговорим о специфике разных систем. Самая простая и распространённая — это FAT, File Allocation Table, «таблица расположения файлов». У неё есть несколько вариаций: FAT12, FAT16, FAT32 и exFAT, она же FAT64. Число в названии — это размер номера блока в битах.
Если вам показалось, что 12 бит для номера блока в FAT12 — это мало, то вы абсолютно правы! Эта операционная система изначально могла работать с разделами до 2 МБ, а с принудительным увеличением размера блока — с разделами до 32 МБ. Сейчас это кажется смешными значениями, но в 1980-х, когда применялась FAT12, этого было более чем достаточно. На современных флешках вы, скорее всего, встретите FAT32 или FAT64, и там размер раздела будет варьироваться от 8 ГБ в FAT32 до 16 ЭБ в FAT64.
Интересно, что во всех системах FAT максимальная длина имени файла или каталога — 8 символов, а для хранения расширения файла отведено 3 символа. «Как так, я же спокойно могу записать на флешку файл с длинным именем?» — скажете вы. И будете правы.
Но если вы посмотрите на свою флешку с помощью специальной утилиты, то увидите, что ваш файл с именем Squid_Game_S2E01.mkv на самом деле называется Squid_~1.mkv.
Всё остальное имя файла хранится в специальной надстройке и занимает дополнительное место (мало места, если быть честным), а ваша операционная система не хочет раздражать вас этими короткими именами и сразу показывает длинное имя. Ещё FAT редко пересчитывает свободное место, вместо этого она хранит в табличке с файлами запись о количестве свободных блоков, но старается обновлять это число, чтобы информация была актуальной. При помощи специальной утилиты можно вручную поменять количество свободных блоков — и из флешки на 4 ГБ сделать флешку на 20 ТБ. Правда, записать столько данных вы туда всё равно не сможете (а жаль).
Поговорим ещё о проблеме фрагментации файлов в FAT. Эта система распределяет блоки файлов, проходя от начала к концу в поисках свободного места. Поскольку информацию, разделённую на блоки, она последовательно записывает в каждый свободный слот, блоки файлов на диске могут быть сильно перемешаны, от этого их чтение замедляется.
Для исправления этого недостатка создали программу дефрагментации. Она считывает разрозненные блоки файла и записывает их заново, единым блоком. При регулярной дефрагментации FAT-диска он будет как новенький!
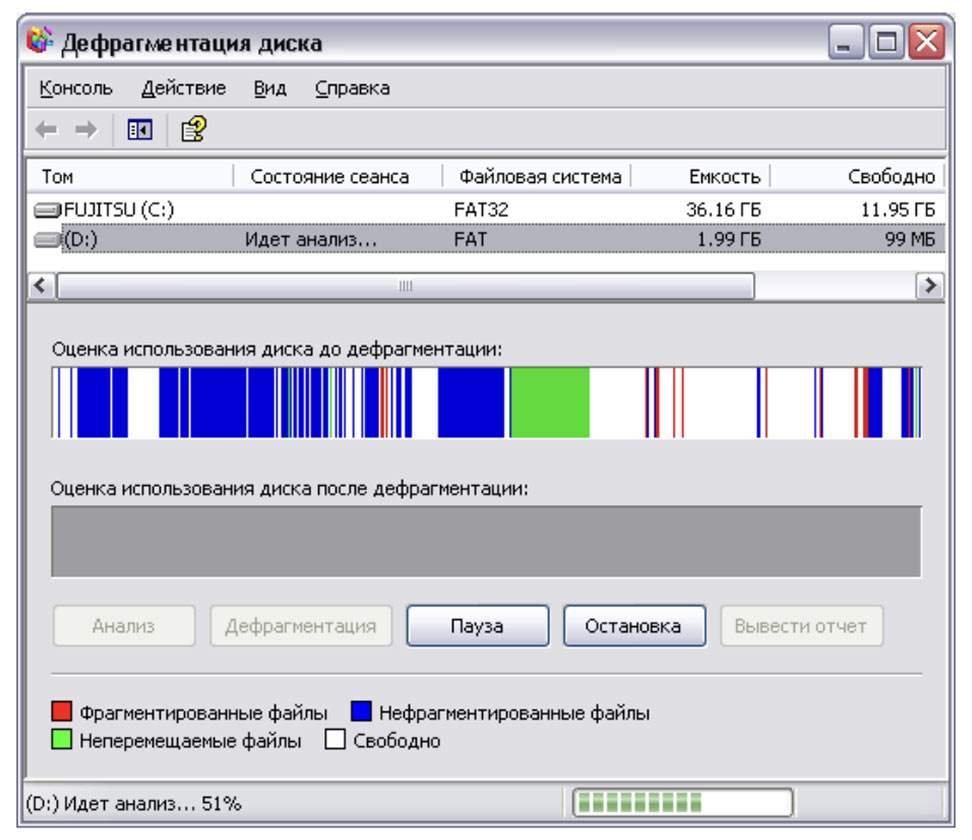 Дефрагментация
Дефрагментация
Другая файловая система, NTFS, имела много преимуществ перед FAT.
Например, в FAT метаданные о файлах хранились отдельно, в виде дополнительного файла, а в NTFS — в таблице с файлами. Там содержалась информация о правах доступа, это позволяло разграничивать, кто какие файлы может читать и менять.
Хорошая идея — защитить файлы операционной системы от случайного изменения. Также оказалось удобно добавить в метаданные информацию о характеристиках файла, например битрейт для аудио и видео или размер картинки. Другой важной новинкой стало то, что у файлов появились потоки данных, streams. Это позволило хранить в одном месте несколько версий файлов (видели вкладку «Предыдущие версии» в свойствах файла?) и держать там дополнительные данные: например, некоторые антивирусы отмечают файлы, которые они проверили.
Последним важным улучшением стала возможность вести журналы, то есть записывать всю историю работы с файлами на этом диске. Это, конечно, сильно нагружает файловую систему, но очень помогает в отладке и поиске проблем. А ещё NTFS умеет экономно хранить маленькие файлы. В табличке отведено очень много места для имени файла. Если файл настолько мал, что его можно записать после собственного имени, эта система не выделяет блок на диске, а умещает файл прямо в табличку.
Появилось и ещё несколько удобных штук, преимущественно для серверной инфраструктуры: например, иерархическое назначение прав, возможность задать квоты на использование места и так далее. Если вы используете компьютер под управлением Windows, скорее всего, на ваших дисках именно NTFS.
И ещё парочка систем!
Рассмотрим другие системы: HFS и APFS для компьютеров Apple, ext, с которой работает Linux, и XFS. Они организованы по-разному, но имеют много похожих принципов.
Первое, что бросается в глаза, это разница в подходе к именам файлов и папок. В Windows вы не можете создать рядом File1.txt и file1.txt, потому что с точки зрения тамошних файловых систем это будет один и тот же файл. А вот в этих файловых системах учитывается разница между строчными и заглавными буквами, так что файлы будут спокойно лежать рядом и не мешать друг другу.
Ещё в них ограниченное распределение прав на файлы и папки. У каждого файла или папки есть пользователь-владелец и группа-владелец, а также назначенные права «читать», «писать» и «выполнять» для группы и для владельца. После NTFS, где вы могли назначить файлу сколько угодно прав, это кажется недостаточным, но при вдумчивом подходе к организации прав пользователей это не будет проблемой.
Также, в отличие от NTFS, где каждому разделу диска присваивалась буква латинского алфавита, файловые системы HFS и APFS содержат всё в едином дереве каталогов. Например, если у вас есть диск с вашими рабочими файлами и диск с системой, то в Windows это могли бы быть диски D: и C:. А в этих файловых системах системный диск станет /, то есть корневой папкой, а диск с вашими файлами, скорее всего, будет /home/user, то есть просто выглядеть как папка внутри. С непривычки это сбивает с толку, но на самом деле даёт много удобства и гибкости.
Стоит упомянуть виртуальные и сетевые файловые системы. Их очень много, и у каждой обычно есть своя специфика, но все они служат надстройкой над «реальной» системой и обращаются к ней, когда им нужно работать с папками и файлами.
Обычно они повторяют принципы распределения прав или используют таковые из файловых систем, на которых на самом деле работают (если вы залезете в сетевую папку в системе Windows, то протокол проверит, какие права выданы на файлы в NTFS пользователю, под которым вы работаете), и предоставляют иерархический вид файлов и каталогов.
Ну и напоследок...
Сложно сказать, когда именно появились файловые системы. В XIX веке для жаккардовых ткацких станков использовали карточки с отверстиями, которые определяли получающийся узор. И их хранили стопочками в каталогах.
Потом первые компьютеры использовали перфокарты, те же бумажные и картонные таблички с отверстиями. А позже начали использовать магнитные ленты для записи данных. Конкретное расстояние на этой ленте оператор подписывал ручкой. И всё убиралось в каталоги — большие железные шкафы с выдвижными ящиками.
Буквально, бобина магнитной ленты, на которой было написано «0–2 м — данные Боба, 2–7 м — данные Алекса, 7–20 м — танцевальная музыка», могла лежать в каталоге, в ящике «Дела на потом».
Сложно назвать это файловой системой, но узнаваемые принципы уже прослеживаются. Затем по такой же схеме использовались аудиокассеты.
 Вроде бы и не похоже, но вот носитель — и понятно, где и что на нём хранится. В целом чем не файлы?
Вроде бы и не похоже, но вот носитель — и понятно, где и что на нём хранится. В целом чем не файлы?
В 50-х годах для компьютеров тех времён было несколько систем, где жёсткие диски делились между пользователями. Например, IBM 305 RAMAC в 1956 году или IBM 709 с поддержкой Compatible Time-Sharing System в 1958. У каждого пользователя был свой раздел диска, заданный смещением от начала, и каждый сам должен был указывать, в каких блоках будет храниться файл. По сути, пользователь руками делал то, чем сегодня занимаются драйверы диска.
В 1964 вышла операционная система Multics, в которой впервые появились файлы и папки в привычном нам виде. В 1969 была создана UFS, Unix File System, а в 1977 — FAT для MS-DOS.
В это время выходило немало и других операционных систем, у которых были свои файловые системы, но у них ещё не было названий, и отдельно они не сохранились. В 1984 году появилась MFS, Macintosh File System, для компьютеров Macintosh от Apple, которая потом стала HFS для macOS.
В дальнейшем файловые системы развивались, следуя за увеличением размера дисков и повышением требований к надёжности и скорости, пока мы не пришли в эру интернета. Понадобилось иметь много гибких вариантов файловых систем для разных случаев, а ещё появилась виртуализация и распределённые системы, которые потребовали таких же файловых систем для себя...
Но это уже совсем другая история!
Поговорим об интернете!
А также о том, для чего нужны все эти соединения, маршрутизаторы, адреса и протоколы
Интернет повсюду вокруг нас: телефоны, компьютеры, игровые приставки, светофоры и умные чайники — все они ходят туда, а часто и вовсе сидят в сети непрерывно.
Интернет стал простой и привычной частью нашей жизни: мы ищем ответы в онлайн-поисковиках, общаемся в мессенджерах, чистим спам в почте и каждый раз огорчаемся, когда обновления из интернета не вовремя прилетают на наши устройства. Но откуда берётся эта вся информация и как попадает к нам?
Что такое интернет
В самом названии Internet есть слово net, то есть «сеть». Интернет раньше так и называли: «поискать информацию в сети», «загрузить в сеть» — так говорили наши родители. Или бабушки с дедушками.
И это очень правильное описание структуры интернета. Представьте себе рыболовную сеть, состоящую из кучи верёвочек и узелков.
Каждая верёвочка — это соединение, каждый узелок — маршрутизатор.
Представьте: в одном углу сети лежит ваш телефон, в другом — сервер Яндекса, а вы хотите узнать погоду на завтра. Как информации добраться от одного угла до другого? Каждый узелок по дороге (маршрутизатор) знает только соседние узелки и пути к ним, а также путь «по умолчанию», куда отправляет все неизвестные маршруты. Ваш телефон спросит у ближайшего узелка: «Мне нужен сервер Яндекса, куда мне?» Сервер далеко, узелок не знает ответа, поэтому скажет: «Прямо и наверх, спроси там». Этот процесс будет повторяться до тех пор, пока ваш запрос не дойдёт до узелка, соседнего с сервером. При этом сам запрос запоминает маршрут, по которому шёл. Он возьмёт нужные данные и той же дорогой вернётся в ваш телефон. Надеемся, было понятно!
Аналогия с рыболовной сетью очень хорошо описывает структуру интернет-соединений. Вы можете порвать много верёвочек, повредить много узелков, но останутся другие, и информация продолжит передаваться по сети. А вот если у вас дома сломается Wi-Fi-роутер (он служит вашим первым узелком), то вы не сможете отправить запрос. Для смартфонов такими первыми узлами работают вышки сотовой связи, они же базовые станции.
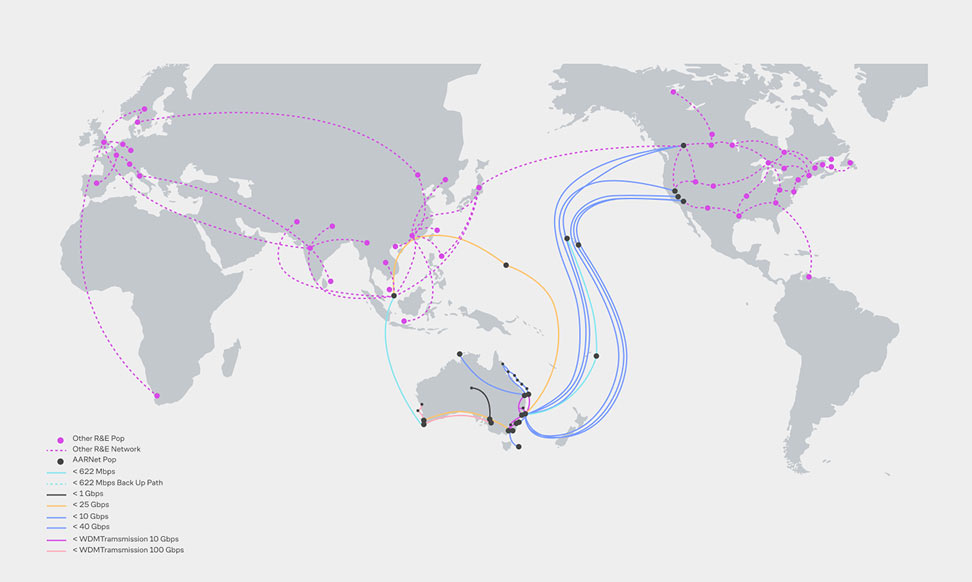 Одна из карт глобальных связей интернета. Попробуйте представить, каким маршрутом пойдёт ваше сообщение для друга в Австралии
Одна из карт глобальных связей интернета. Попробуйте представить, каким маршрутом пойдёт ваше сообщение для друга в Австралии
Что такое протокол
При отправке запроса и получении ответа запрос делится на части — и каждая часть может пойти своим маршрутом, чтобы распределить нагрузку на сеть более равномерно.
При этом части запроса нумеруются, создаётся «порядок сборки», поэтому понятно, какая часть за какой должна идти. А если что-то потеряется по дороге, об этом станет известно — и эту часть отправят ещё раз, возможно, другим маршрутом. Этот механизм называется «протокол управления передачей», Transmission Control Protocol, сокращённо TCP.
Вторая важная часть работы интернета — это адресация. Было бы странно, если бы этот механизм работал без какой-то чёткой системы адресов. Все бы запутались и не знали, что где искать. Такая система называется «межсетевой протокол», Internet Protocol, сокращённо IP.
Каждому устройству в сети (маршрутизаторам тоже) даётся IP-адрес, с помощью которого это устройство можно найти. Адрес состоит из четырёх чисел, каждое от 0 до 255. Записи адреса обычно получаются такими: 74.56.129.252. Все маршруты в интернете построены от одних таких адресов к другим, адрес есть у каждого сервера и каждого клиента. Проблема этого подхода в том, что при такой комбинации чисел у нас может быть всего 4 млрд адресов. В 1981, когда его только придумали, казалось, что этого достаточно, но в 2000 году адреса начали заканчиваться. На смену этому подходу должен прийти обновлённый IPv6, который состоит из 32 чисел от 0 до 15, таких адресов должно быть примерно 5 × 10²⁸.Записи в нём выглядят так: 2001:0db8:11a3:09d7:1f34:8a2e:07a0:765d (в двоичной записи один байт — это как раз от 0 до 15, или от нуля до f, чтоб записывать одним символом).
Правда, переход на новый протокол IP буксует, большая часть интернета продолжает использовать старую версию с четырьмя числами.
Также для экономии адресов есть специально выделенные «частные сети». Это обычные домашние или корпоративные сети, при использовании которых каждый подключённый клиент недоступен напрямую из интернета. Самый простой пример — обычная домашняя сеть.
Она выглядит как Wi-Fi-роутер, куда приходит кабель от провайдера. Роутер раздаёт интернет на ноутбук, умную колонку, телевизор, телефон и приставку. У каждого из этих устройств есть свой внутренний адрес в рамках домашней сети, но из интернета по нему обратиться к устройству нельзя. А ваш Wi-Fi-роутер перенаправляет запросы по нужным адресам и потом возвращает ответы клиентам. Шесть устройств работают одновременно, занимая всего один адрес в интернете.
Может быть, вы сталкивались с термином «белый IP» у провайдеров. Если ваш провайдер так организует сеть, но эта опция у вас не активна, роутер будет подключён через внутреннюю сеть провайдера — и даже не будет выходить напрямую в интернет.
Адресная книга, протокол и шифр
Следующий важный элемент работы интернета — это адресная книга. Согласитесь, заучивать, что надо набирать 77.88.55.88, чтобы попасть в поиск Яндекса, не очень удобно. Для этого придумали систему доменных имён, Domain Name System, сокращённо DNS. Это специальные серверы, задача которых — уметь отвечать на вопрос «по какому адресу находится вот такой сайт». Это буквально адресная книга. Конечно, со своими нюансами, потому что интернет очень большой.
Все имена состоят из доменов, которые различаются по уровням. Чем ближе к концу записи текст, отделённый точками, тем более высок уровень домена. Домены первого (высокого) уровня, top level domain, — например, .ru в weather.yandex.ru. В этом примере .yandex — домен второго уровня, а weather — третьего. Домены третьего и более низких уровней часто называют поддоменами. Основная идея такой иерархии в том, что мы можем оставить для центральных и мощных серверов управление доменами первого уровня и передать конечным владельцам сайтов управление доменами уровнем ниже. Если вы хотите создать свой сайт в домене .ru, вы отправляете заявку организации, управляющей доменом (эта процедура называется «регистрация домена»), и получаете в управление свой сайт, на котором можете делать любые домены уровнями ниже, просто настроив свой сервер DNS правильно.
Многие домены первого уровня называются национальными, потому что содержат прямую отсылку к стране, которой принадлежат. Например, домены .ru и .рф означают Россию и управляются соответствующей организацией, а домен .us означает США. Впрочем, если вы откроете сайт любого регистратора доменов, вы увидите сотни вариантов, которые можно зарегистрировать из любой страны мира, здесь нет чёткой корреляции.
До появления глобальной системы доменных имён на компьютерах был специальный файл, куда вручную заносились записи о соответствии имени и адреса, и при запросе можно было набрать введённое имя. Такие файлы остались с нами до сих пор, это часть сетевой инфраструктуры операционных систем. Вы можете найти на своём компьютере файл hosts (для Windows это Windows\System32\Drivers\etc\hosts на системном диске, для Мака — /etc/hosts), вписать туда mysite 185.15.59.224, и когда вы откроете браузер и наберёте в адресной строке mysite, попадёте в Википедию. Но работать это будет только у вас.
Это может быть забавно, но мы не рекомендуем без необходимости трогать системные файлы.
Также стоит рассказать про шифрование. Как мы уже выяснили, ваш запрос и ответ каждый раз проходят через неизвестные узлы по неизвестному вам маршруту. Если по дороге попадётся владелец узла, который решит, что ему очень интересно, что за информация проходит через него, а вы вбили данные карточки для оплаты заказа в интернет-магазине, он эти данные увидит. Согласитесь, так себе перспектива.
Так что один из стандартов в интернете — использование шифрования, основанного на сертификатах. Если очень кратко: при установке соединения вы и сервер выбираете временные секретные ключи и шифруете с их помощью все отправляемые данные, так что узнать, что было до шифрования, можете только вы или сервер, но никто по пути. Поэтому обращайте внимание на предупреждения браузера о незащищённом подключении или проблемах с сертификатом при работе в интернете, чтобы ваши данные не попали не в те руки.
И последнее, чего хотелось бы коснуться, это протоколы. Есть много разных способов использовать интернет кроме просмотра сайтов: отправка электронных писем, просмотр видео, общение в мессенджерах. Эти данные требуют другого подхода к организации и пересылке, так что при обмене информацией присутствует понятие «протокол». Обычно они определяются содержимым данных, которые вы отправляете и получаете, и часто различаются сетевыми портами на конечных серверах. Порт — это просто число после адреса или имени сервиса, к которому вы обращаетесь.
Например, 80-й и 443-й порты — это обычный HTTP, который используется для просмотра сайтов, 25-й — это протокол для получения и пересылки электронных писем, а протокол 53 используется для запросов доменных имён. Вам не обязательно знать и использовать эти порты, просто держите в голове, что по одним и тем же маршрутам может ходить разная информация с разным назначением.
Ну что, базово мы разобрались с интернетом. Приятно знать, как работает всё, включая эту статью.
Едем дальше!
Кто говорит на языках программирования
И как эти языки развиваются, становясь всё удобнее для человеков (и машин)
Программы, упрощающие нашу работу на компьютере, пишутся на языках программирования. Языки программирования также написаны на языках программирования. Так мы, люди, шаг за шагом идём к взаимодействию с машиной на простом человеческом языке. Ну наконец-то!
Как всё начиналось
Знаменитая статья Алана Тьюринга, которую позже перепечатали под названием «Может ли машина мыслить?», сперва была опубликована в научном журнале Mind в 1950 году под заглавием «Вычислительные машины и разум» (Computing Machinery and Intelligence).
Но первый язык программирования появится значительно раньше. Его предшественником можно назвать машинный алгоритм Ады Лавлейс, дочери лорда Байрона. Названная в честь сестры поэта, Ада за всю жизнь так и не увидела отца — из-за развода родителей. Анна Изабелла Байрон, мать Ады, постаралась увлечь свою дочь математикой, опасаясь, что та, как и её отец, займётся поэзией.
Познакомившись с Чарльзом Бэббиджем, проектировщиком аналитической машины, Ада стала его соратницей и помощницей. Хотя Чарльз Бэббидж так и не построил работающий прототип, многие его наработки помогли другим изобретателям того времени. Только сыну Бэббиджа удалось закончить работу отца.
Понимая принципы действия аналитической машины, Ада написала первую в мире программу, введя понятия «цикл», «прерывание» и другие, знакомые теперь каждому программисту.
Более того, в своих записях она предполагала, что аналитическая машина способна создавать алгебраические формулы, а в перспективе — писать музыку и картины. Нынешнее развитие искусственного интеллекта показывает, насколько она была права.
В ходе дискуссий, сопровождавших разработку первого лампового компьютера под названием ENIAC, Джон фон Нейман и его коллеги составили документ, который описал созданное ими устройство, — это способствовало появлению машинных языков.
Затем Кэтлин и Эндрю Бут разработали проект раннего цифрового компьютера, так называемого автоматического релейного калькулятора (Automatic Relay Calculator). В далёком 1946 году Эндрю Бут в основном занимался конструированием ЭВМ, а Кэтлин Бут — программированием. Учитывая принципы построения цифровых машин, Кэтлин написала команды, на основе которых в дальнейшем был спроектирован язык Assembler.
Язык машинных инструкций состоит из комбинаций нулей и единиц, так что он непонятен для человека.
Поэтому для написания программы человеку необходимо описание машинных команд в более удобной форме, например в виде текстовых мнемоник. Таким описанием и стал Assembler.
Но уже тогда становилось понятно, что недостаточно просто писать команды для компьютера, необходимо решать инженерные задачи и описывать структуру программы более полно. Например, в 1843 году Ада Лавлейс написала программу для вычисления чисел Бернулли — последовательности рациональных чисел, играющей важную роль в математике. Такое описание требует сложных для машины абстракций. А языки, подходящие для работы с такого рода абстракциями, называют высокоуровневыми — в противовес низкоуровневым, машинным.
Ассемблер не был единственным языком программирования в 40-е и 50-е годы: в это же время появляются Plankalkül, Short Code и другие. Они уже были высокоуровневыми в нашем понимании, но ещё простыми, процедурными языками.
С середины 50‑х годов создавался высокоуровневый язык Fortran. И в 1957 появился компилятор для этого языка, позволяющий перевести код, понятный пользователям, на машинный язык. Удобство Fortran и эффективность компилятора способствовали росту популярности. Уже к 1963 году было создано более 40 компиляторов для большинства распространённых ЭВМ. Таким образом, Fortran стал первым широко распространённым языком программирования.
Не зря профессора из знаменитой советской книжки про компьютеры звали Фортраном!
В 1958 году в Германии и США создали Algol. В этом языке реализовали концепцию структурного программирования: программа разбивалась на подпрограммы, что упрощало разработку и поиск ошибок. До появления Algol программа была неструктурированной последовательностью команд. Наряду с Fortran, применявшимся для вычислений в научных работах, Algol стал популярен в академических кругах.
Язык Cobol, максимально приближенный к английскому языку и понятный даже тем, кто не владел программированием, был создан в 1959 году. Новшеством этого языка стало введение структуры данных «запись», объединяющей данные разного типа, например строки, числа или даты. Новые языки позволяли писать программы без лишнего погружения в машинный код, становились процедурными, стремились к доступности и упрощению.
В основе — простота
И наконец, язык BASIC был разработан Томасом Курцем и Джоном Кемени в 1964 году. В самом названии языка заложено его ключевое свойство — простота. Задуманный для пользователей без технического образования, этот язык открыл для многих программирование. Когда я только познакомился с компьютером, это был первый язык, который я узнал.
«Бейсик» помог мне увидеть компьютер с другой стороны: не как средство для игр или инструмент офисной работы, а как машину, творящую чудеса.
Идея разработки языка, доступного не только программистам, но и пользователям, посетила также Никлауса Вирта. Ранее учёный принимал участие в разработке языка Algol. Используя полученные знания, в 1972 году он написал язык с доступным для понимания синтаксисом и упрощённой компиляцией. Компилятор, созданный для Pascal, трансформировал изначальный код в код языка Ассемблер, для работы с которым требовался только интерпретатор. Это нововведение потом применили при написании языка Java.
Позднее Pascal зарекомендовал себя как язык для обучения программированию. А BASIC после появления персональных компьютеров стал самым доступным для пользователя языком программирования на них.
До сих пор язык BASIC помогает многим людям там, где нужно простое программирование. Например, его диалект, Visual Basic, используется для работы с графическими интерфейсами, требуется для разработки профильных приложений, встроен во многие офисные программы.
В 1969 году разработали операционную систему, предназначенную для одновременной работы нескольких пользователей. С полуночи 1 января 1970 года начинается «эпоха UNIX», компьютеры всего мира отсчитывают время от этой даты.
В 1971 году был изобретён микропроцессор, после чего, в середине 70‑х, началось массовое распространение персональных компьютеров. Появление ОС широкого профиля требовало создания языков для их написания. Такими языками стали C и C++.
И кое-что посложнее
Синтаксис языка C сопоставим с типичными машинными инструкциями. Но при этом язык был более высокоуровневым, поддерживал типизацию данных и работал с привычными для программистов абстракциями: числами, датами, строками, файлами. Этот язык, можно сказать, был создан для написания операционных систем — и до сих пор остаётся востребованным для таких задач. Язык программирования C разрабатывался сотрудниками компании Bell Labs Кеном Томпсоном и Деннисом Ритчи на базе ранее созданного ими языка B. Видно, что с названиями ребята не очень заморачивались...
Также Томпсон и Ритчи создали операционную систему UNIX. Первая редакция ОС UNIX была написана на языке Assembler, но он не решал все поставленные задачи. Вторая редакция ОС UNIX была написана на языке B. Редакция со встроенным компилятором языка C, во многом на нём написанная, стала третьей по счёту и вышла в 1973 году.
С появлением UNIX и подобных операционных систем программисту больше не нужно было понимать, как технически работает его компьютер. Вместо этого ему нужно было понимать, как работает операционная система. Теперь можно было не думать о байтах и битах — предстояло думать о том, как описать реальные объекты на языке программирования. Для этих задач язык C не подходил. Это и послужило толчком к созданию языка C++ и дальнейшему развитию концепции объектно ориентированного программирования.
Одним из первых языков, оперирующих не командами, а объектами, был язык Simula 67. Написанный в 60-е годы, он во многом опередил своё время. Синтаксис этого языка больше напоминает языки процедурного характера, такие как BASIC.
В 80‑х годах Бьёрн Страуструп, работая над задачами теории очереди, пришёл к выводу о необходимости создания языка, который, с одной стороны, будет быстрым, а с другой — будет описывать сложные объекты. Он взял за основу язык C и дополнил его конструкциями из языка Simula. Так появился C++. В итоге C породил целое семейство языков с похожим синтаксисом, их называют C-подобными языками: С++, Java, С#.
В 1981 году появились IBM-PC-совместимые компьютеры. Это дало толчок к развитию таких систем, как MS-DOS. Встал вопрос о разработке массовых программ со сложным графическим интерфейсом. Языки BASIC и Assembler всё ещё оставались востребованными, но постепенно уступали C-подобным языкам.
Уже с середины 80‑х начала широко распространяться клиент-серверная архитектура. По мере её развития требовались новые подходы в языках программирования, что привело к написанию таких серверных языков, как Python, PHP и другие.
1991 год многое изменил: появился протокол HTTP, идентификатор URL и такое явление, как Всемирная паутина (World Wide Web). Мир стал глобальнее и ближе.
История развития языка клиентских приложений JavaScript тесно связана с историей развития браузеров. Браузер NCSA Mosaic, наряду с протоколом HTTP обеспечивший доступность интернета, был выпущен в 1993 году. Его основными разработчиками были Марк Андриссен и Эрик Бина. Вскоре после разработки Mosaic Марк Андриссен покинул NCSA и вместе со своими друзьями основал компанию Netscape Communications Corporation, основным продуктом которой стал браузер Netscape.
Марк Андриссен, его коллега по Netscape Communications Брендан Айк и Билл Джой, сотрудник Sun Microsystem, написали JavaScript, язык для веб-дизайнеров и программистов, не обладающих высокой квалификацией.
Они хотели создать язык, который, с одной стороны, будет встраиваться в саму страницу, а с другой — соединять разрозненные мультимедийные части. Преальфа языка была включена в Netscape 2. А 4 декабря 1995 года язык был переименован в JavaScript, для этого была получена лицензия у компании Sun. Его пришлось переименовать из-за популярности слова Java в среде программистов — в связи с тесным сотрудничеством компаний Sun и Netscape и их общей позицией по отношению к развитию языка.
JavaScript сделали стандартным языком браузеров. И он остаётся таким по сей день.
Битва браузерных языков
Взяв за основу браузер Mosaic, компания Microsoft разработала браузер Internet Explorer, по умолчанию включённый в набирающую популярность операционную систему Windows. В отличие от Netscape Navigator, Internet Explorer был доступен бесплатно. Такая политика компании Microsoft привела к её победе в первой войне браузеров. В 1999 году рынок коммерческих браузеров перестал существовать, Internet Explorer захватил 99% рынка. После того как компания Netscape в связи с долгами была перекуплена провайдером AOL, разработчики выложили исходный код своего браузера в открытый доступ, что дало толчок к появлению браузера Mozilla.
В борьбе за конкурентное преимущество компания Microsoft в 1996 году выпустила аналог языка JavaScript, названный JScript. Microsoft и Netscape вносили всё больше несовместимых друг с другом улучшений в разрабатываемые языки.
После победы над Netscape не существовало единого стандарта скриптового языка браузера.
Вопрос стал настолько острым, что в том же 1996 году по инициативе компании Netscape ассоциация ECMA начинает стандартизацию семейства JavaScript-подобных языков. Спецификацию приняли в июне 1997 года. Позднее в семейство ECMA-языков вошёл ещё один язык, активно повлиявший на облик интернета в 2000 годах: язык Flash-приложений ActionScript. Хотя технология Flash была стандартом мультимедиа и браузерных игр в 2000–2010 годах, в ней неоднократно находили уязвимости. В 2015 компании Facebook и Mozilla призвали к отказу от использования технологии, за этим последовал массовый бойкот со стороны браузеров.
Попытки создать портативное устройство предпринимались ещё в 90‑х. В рамках одного из проектов, опередивших своё время, — Star7 компании Sun Microsystems — был написан язык Java, сперва использовавшийся как язык серверных приложений. Позже он перешёл в нишу мобильных устройств и стал основным языком ОС Android.
Портативные компьютеры стали популярны благодаря Стиву Джобсу и его компании Apple. В 2007 году появляется первый iPhone. Активно ворвавшись в гонку мобильных устройств, он на долгие годы определил представление пользователей о мобильном интернете. Вместе с появлением новых устройств появились и новые требования.
Началась новая война браузеров, закончившаяся победой Webkit. Сегодня на основе Webkit написано большинство браузеров.
А разработка JavaScript-интерпретатора V8, созданная для браузера Chromium, позволила использовать JavaScript вне браузеров при помощи платформы Node.js.
В 2000-е, после появления архитектуры x86-64, встал вопрос о создании языков, которые заменят C. Язык C разрабатывался до появления IBM-PC-совместимой архитектуры, и некоторые его особенности были продиктованы спецификой архитектуры PDP-11, для которой писалась операционная система UNIX. Сам язык C далеко не всегда точно отражал особенности аппаратной архитектуры, если она отличалась от архитектуры PDP-11.
Требовались языки, которые заменят C, прежде всего в применении новых возможностей процессоров, например многопоточности. Такими языками стали Rust и Go, разработанные в конце 2000‑х и начале 2010‑х.
Развитие аналитических инструментов и появление большого объёма данных продолжали перекраивать ландшафт языков программирования. В 2015 году появилась платформа TensorFlow, которая дала вторую жизнь Python. К 2024 Python стал одним из самых популярных языков.
Визуальное программирование и общение с машиной на человеческом языке могут заменить языки программирования там, где требуются новые средства решения рутинных задач. А появление больших языковых моделей и No-code-платформ подтверждает этот тренд. Сегодня даже школьник может решить сложные задачи через простые интерфейсы.
Ну а вы теперь знаете обо всех основных языках программирования: откуда они появились и для чего нужны. Отличненько, едем дальше!
Что такое исполняемый файл
Раньше его покупали на «Горбушке», а сегодня можно сделать своими руками
Мы кликаем на иконку на рабочем столе и через несколько мгновений уже играем в любимую игру или работаем с документом в офисном приложении. Но что и как происходит в компьютере за эти мгновения? Давайте разберёмся.
Что такое исполняемый файл
То, что выглядит для нас как иконка с подписью, для компьютера — ссылка на конкретный файл, а двойным кликом мышью по иконке мы даем команду компьютеру открыть этот файл.
В операционной системе нашего компьютера (пока для простоты будем считать, что это Windows) прописаны правила, определяющие, какими программами открывать файлы разных типов: если кликнутый файл был с расширением .docx, он откроется в текстовом редакторе, если с расширением .py — выполнится в интерпретаторе языка Python, с расширением .bat/.cmd — командным интерпретатором.
Однако есть уникальный тип файла, который ОС выполняет без программ-посредников...
Это бинарный исполняемый файл, содержащий прямые инструкции на машинном коде для процессора. В Windows такие файлы имеют расширение .exe (от англ. executable — исполняемый). Вот фрагмент бинарного исполняемого файла в шестнадцатеричном представлении:
BB 11 01 B9 0D 00 B4 0E 8A 07 43 CD 10 E2 F9 CD 20 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21
Это не просто набор символов, а код программы, выводящей на экран сообщение «Hello World». Согласитесь, для нас это выглядит как шифр, но для процессора — это понятные команды.
Как создаются исполняемые файлы?
Первым программистам приходилось не только составлять программы, но и переводить их в бинарный код вручную. Чтобы облегчить их работу, создали Assembler — программу-транслятор, которая переводит с низкоуровневого языка программирования в двоичный код. Вот так выглядит текст программы «Hello World» на assembler:
.model small
.stack 100h
.data message db 'Hello World',13,10,'$' ;
.code
start:
mov ax, @data
mov ds, ax
mov dx, offset message
mov ah, 09h
int 21h
mov ah, 4Ch
int 21h
end start
Код стал читабельнее, но не сильно проще: ведь «Ассемблер» — высокоуровневый язык, каждая его команда соответствуют отдельной инструкции процессора. И быстро писать на этом языке не получится. А программ со временем требовалось всё больше и больше, и, чтобы ускорить процесс их разработки, были придуманы высокоуровневые языки. На большинстве из них «Hello world» выглядит приблизительно так:
print("Hello world")
Языки высокого уровня — это набор команд и синтаксических правил языка, и программа-транслятор, переводящая программы с этого языка в машинный код. Трансляторы по способу работы делятся на компиляторы и интерпретаторы.
Интерпретаторы выполняют код программ построчно, переводя каждую строку с языка высокого уровня в блок байт-кода для процессора. Интерпретируемый код выполняется медленнее, но его быстрее отлаживать и модифицировать.
Компиляторы переводят сразу весь текст программы в байт-код, и записывают его в файл, называемый объектным. Затем объектный файл компонуется с библиотеками в бинарный исполняемый файл.
Если исполняемый файл содержит в себе всё необходимое для своей работы, он может быть выполнен на любом компьютере без дополнительных действий, и называется портативным («portable»). Такими были почти все программы на заре эры персональных компьютеров.
Но со временем программы усложнились, стали многомодульными, им необходимы мультимедиа-данные и внешние библиотеки, поэтому теперь большинство программ не станут работать без предварительной установки (инсталляции) на компьютере.
Так что ещё одна забота программиста — создание установочного пакета (инсталлятора). Инсталлятор — это исполняемый бинарный файл, который содержит внутри архив всех компонентов программы и специальный скрипт, где расписан процесс установки по шагам. При запуске на компьютере инсталлятор распакует архив и по скрипту распределит модули программы в нужные каталоги, проверит наличие в операционной системе необходимых библиотек, скачает из интернета и установит недостающие, зарегистрирует программу в операционной системе и создаст ярлычки на рабочем столе и в меню «Пуск». Красота!
Как программы попадают на компьютеры?
В корпоративной сфере на все офисные компьютеры софт устанавливают системные администраторы по локальной сети.
Но где обычному человеку брать программы или установочные пакеты? До широкого распространения интернета «домашние» пользователи передавали их из рук в руки на дискетах, CD-дисках и флешках...
А также — о ужас! — покупали диски с программами на компьютерных рынках.
Но это было крайне небезопасно из-за компьютерных вирусов, и очень неудобно: просто представьте, что за нужной программой вам нужно ехать после работы на рынок на другом конце города.
Поэтому с проникновением интернета в каждый дом физические способы получения программ были вытеснены скачиванием их с сайтов компаний-разработчиков или с сайтов, содержащих каталоги программ. И если официальные сайты гарантировали отсутствие вирусов, то при скачивании из анонимных сетевых каталогов пользователь получал «кота в мешке», иногда довольно злобного.
Бродить по всемирной сети в поисках нужной программы, конечно, комфортнее, чем по условному компьютерному рынку «Горбушка».
Но было бы куда удобнее собрать все проверенные, безопасные программы в одном надежном глобальном сетевом каталоге. Идея магазина приложений была реализована в 2004 году в виде Windows Marketplace.
А ещё очень удобно было бы иметь в операционной системе программу, которая периодически проверяет актуальность всех установленных программ, незаметно для пользователя скачивает и ставит обновления (как «Центр Обновления» Windows, только для программ).
Эта концепция пришла из мира UNIX и Linux и называется «Система управления пакетами» или «Package manager». Но Windows Marketplace такого не умел, поэтому в 2012 году под влиянием уже существующих Мас App Store и Google Play появился его преемник — Windows Store. Это была уже платформа, сочетающая каталог программ, магазин и менеджер пакетов установки, но... Только для новых проверенных компанией Microsoft программ с интерфейсом Metro, появившимся в Windows 8.
А классические приложения для Windows, которых за примерно 20 лет доминирования операционной системы на рынке было создано несколько миллионов, продолжали пользоваться собственными механизмами обновления или не обновлялись вовсе. Только с выходом Windows 10 магазин приложений (теперь он называется Microsoft Store) и его каталог стали доступны для всех программ. И до сих пор в силу истории развития Windows в ней не работает единый механизм установки и обновления софта, хотя технически он уже есть.
Итак, разобрались с тем, такое бинарные исполняемые файлы в мире Windows, как они создаются и распространяются. А как в других мирах?
Исполняемые файлы в других операционных системах
Во всех сегодняшних операционных системах есть бинарные исполняемые файлы, но у них разный внутренний формат. Поэтому нельзя просто взять и запустить exe-файл из ОС Windows на MacBook, или .bin-файл из Linux на Windows. Но при разнице в деталях общие принципы распространения и установки программ есть во всех операционных системах!
Linux — это целый род операционных систем (на текущий момент более 300 актуальных дистрибутивов), разделенных на семейства. А в каждой семье, как в реальном мире — свои правила.
Хорошо еще, что во всех дистрибутивах этого рода операционных систем единый формат бинарных исполняемых файлов и договоренность присваивать им расширение .bin. Также все дистрибутивы Linux придерживаются одного принципа установки и обновления программ, который называется Система управления пакетами или менеджер пакетов. А вот дальше начинаются расхождения в правилах: пакетные менеджеры и формат пакетов в разных семействах Linux разные, вот самые известные из них:
- RPM и yum используются в дистрибутивах Red Hat, Fedora, Mandriva, openSUSE и других,
- dpkg и apt — в Debian и большом семействе дистрибутивов, основанных на нём: Ubuntu, Astra Linux, Kali Linux, Linux Mint и др.,
- Pacman — в Arch Linux и его семействе: Antergmos, Parabola GNU, ConnochaetOS, Manjaro и др.,
- Portage — в Gentoo Linux и дистрибутивах, основанных на нём.
Каждый из этих пакетных менеджеров работает со своим каталогом программ («репозиторием»). Это может привести, хотя и в редких случаях, к ситуации, когда нужной программы в виде установочного пакета нет ни в репозитории его дистрибутива Linux, ни на сайте автора программы. Тогда linux-пользователь может скачать исходный код нужной программы с сайта автора, своими руками скомпилировать и скомпоновать программу в исполняемый файл, благо, в состав любого Linux входит набор компиляторов для распространённых языков и средства компоновки.
А ещё все пакетные менеджеры — это консольные утилиты, работающие в терминале. Ну а что поделать!
 Менеджер пакетов скачивает список с номерами последних версий программ и обновляет устаревшие через «терминал» в Linux Mint
Менеджер пакетов скачивает список с номерами последних версий программ и обновляет устаревшие через «терминал» в Linux Mint
ОС Linux появилась в 1991 году, когда основным способом взаимодействия человека с компьютером был «терминал», то есть клавиатура и дисплей, способный отображать только буквы и цифры.
Человек вводил команды с клавиатуры, машина отчитывалась о результатах их выполнения на дисплее. Хорошее было время...
Но в последнее время появляется всё больше Linux-дистрибутивов, ориентированных на пользователей, которые привыкли работать в Windows и всё делать мышкой. В составе таких дистрибутивов (Linux Mint, elementaryOS, Manjaro и др.) обязательно есть менеджер установки программ с графическим интерфейсом под мышь, нечто вроде магазина приложений от Microsoft или Apple, только программ немного, зато все бесплатны, это же Linux.
 Менеджер установки программ в Linux Mint
Менеджер установки программ в Linux Mint
В macOS бинарные исполняемые файлы, как правило, имеют расширение .app (application). За установку и обновление пакетов программ отвечает Mac App Store (не путать с отдельным App Store для мобильных устройств на iOS).
Каталог магазина открыт для всех разработчиков программ, но модерируется в соответствии со строгой политикой Apple. В macOS возможна как ручная установка программ, скачанных из интернета (традиционный способ в Windows), так и установка программ из независимых каталогов с помощью консольных менеджеров пакетов (как в Linux), например, Homebrew. Но большинству обладателей MacBook достаточно родного магазина приложений, поскольку он хорошо интегрирован в систему и радует обширным каталогом действительно качественных программ.
Как видите, различий не так много, потому что миры разных операционных систем не изолированы, и разработчики «вдохновляются» идеями друг друга. Ну и прекрасно — а мы едем дальше!
Что такое данные
Документ pdf, qr-код, табло метрополитена, интернет-страница или сигнал светофора — мы сталкиваемся с ними ежедневно. Разберемся, что у них общего
Одно из ключевых понятий в IT — это информация. Философы веками спорят, что это вообще такое, и продолжают до сих пор. Понятие «информация» используется в теории вероятности, статистической физике, кибернетике, теории кодирования и теории информации. Без информации — никуда.
Единицей измерения информации считается бит. Однако на практике чаще используется более удобная единица — байт, состоящий из 8 битов.
 Математик Клод Шенон предложил считать информацию в битах. А вот и он
Математик Клод Шенон предложил считать информацию в битах. А вот и он
Информация — это смысл, который извлекается из данных.
Если информация обретает форму, которую можно пересылать и обрабатывать в программах, она снова становится данными, которые можно измерять в битах и байтах. Если представить память компьютера или телефона как сосуд, то данные — это то, что его заполняет.
Данные — формы представления информации, с которыми имеют дело информационные системы и их пользователи. Каждый день мы сталкиваемся с различными форматами данных: файлами, веб-страницами и другими. Данные передаются, принимаются, перекодируются и интерпретируются программами.
Представим обычную ситуацию: коллега в рабочем чате прислал ссылку на документ. Клик по ссылке — и на экране открылся текст. Но чтобы это произошло, потребовалось множество незаметных для пользователя операций с данными:
- Чат-программа вызвала программу-браузер, передав ему данные, адрес в сети интернет (ссылку коллеги).
- Браузер сформировал и отправил серверу в интернете запрос на данные по этому адресу в формате протокола HTTP (HyperText Transfer Protocol, стандартный протокол передачи данных в интернете).
- Сервер вернул ответ браузеру с данными в формате протокола HTTP.
- Браузер получил HTTP-ответ сервера с запрошенными данными,
Пример заголовка HTTP-ответа:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 1234
В этом примере заголовок Content-Type указывает, что данные — это HTML-документ в кодировке UTF-8. - Браузер сопоставил тип данных из HTTP-ответа сервера с теми типами, которые он умеет отображать. Если этот формат поддерживается браузером (например, HTML, PDF, изображение), мы сразу получим документ на экране. Если формат не поддерживается, полученные данные будут сохранены в файл, а управление будет передано операционной системе.
- ОС, получив файл, проверит список зарегистрированных для его формата приложений и вызовет приложение, зарегистрированное приоритетным для этого формата файла, если такое есть. Если приоритетного приложения нет, операционная система предоставит выбор пользователю.
- Приложение читает файл, данные отображаются на экране.
- Готово, вы великолепны.
Любая программа предназначена для обработки данных. А каждый разработчик должен понимать, какие шаги проходят данные по пути к конечному пользователю. Последовательное описание шагов и преобразований, которые происходят с информацией перед ее отображением — это и есть описание программы. Любая программа имеет доступ к функциям операционной системы или может, используя протоколы передачи данных, получить доступ к другим программам.
Программы обычно взаимодействуют с различными формами данных: файлами, протоколами передачи данных, базами данных и реестрами. Можно сказать, программа оперирует различными данными, записывая их в оперативную память компьютера, а затем удаляет их как мусор.
Предположим, что данные — это номер телефона Яндекс-Музея и рассмотрим несколько примеров размещения данных:
В файле на диске компьютера
Напишем простую программу на языке Python, создав в текстовом редакторе файл main.py:
file = open("museum_number.txt", "w")
file.write("+7 (499) 110-11-33")
file.close()
Эта программа из трёх строк создаст файл «museum_number.txt» и запишет в него номер телефона Яндекс-Музея. Чтобы выполнить данную программу у себя на компьютере, нужно установить в операционной системе пакет языка Python и выполнить команду:
python main.py
Теперь телефон Яндекс-Музея будет всегда под рукой, в файле «museum_number.txt» на диске компьютера.
На сайте в интернете
Если мы хотим сделать номер телефона доступным для всех пользователей интернета, можно поместить его на web-страницу. Для этого создадим простой HTML-документ:
<html>
<head>
</head>
<body>
<a href="tel: +74991101133"> +7 (499) 110-11-33</a>
</body>
</html>
Сохраним его в файл «index.html» и разместим файл на сервере с доменным адресом «ymuseum.ru». Теперь при клике по ссылке https://ymuseum.ru/ у всех пользователей интернета будет открываться наша страница с номером телефона Яндекс-Музея. Ура!
В базе данных
Для хранения больших объёмов данных, их сохранности и быстрого к ним доступа используются специальные программы — базы данных.
Чтобы сохранить телефон Яндекс-Музея в базе данных, нужно создать таблицу. Это почти такая же таблица как в Excel. Только работать с ней нужно не мышкой и клавиатурой, а командами на языке запросов SQL (чаще всего). Создадим базу данных «ab», таблицу «phones», в в которой есть строковые поля «number» и «fio», и запишем в неё номер телефона:
CREATE DATABASE ab;
CREATE TABLE phones (
fio varchar(255),
number varchar(255)
);
INSERT INTO phones (fio, number)
VALUES ('Yandex Museum', '+74991101133');